
Publications
HOTA: A Higher Order Metric for Evaluating Multi-object Tracking
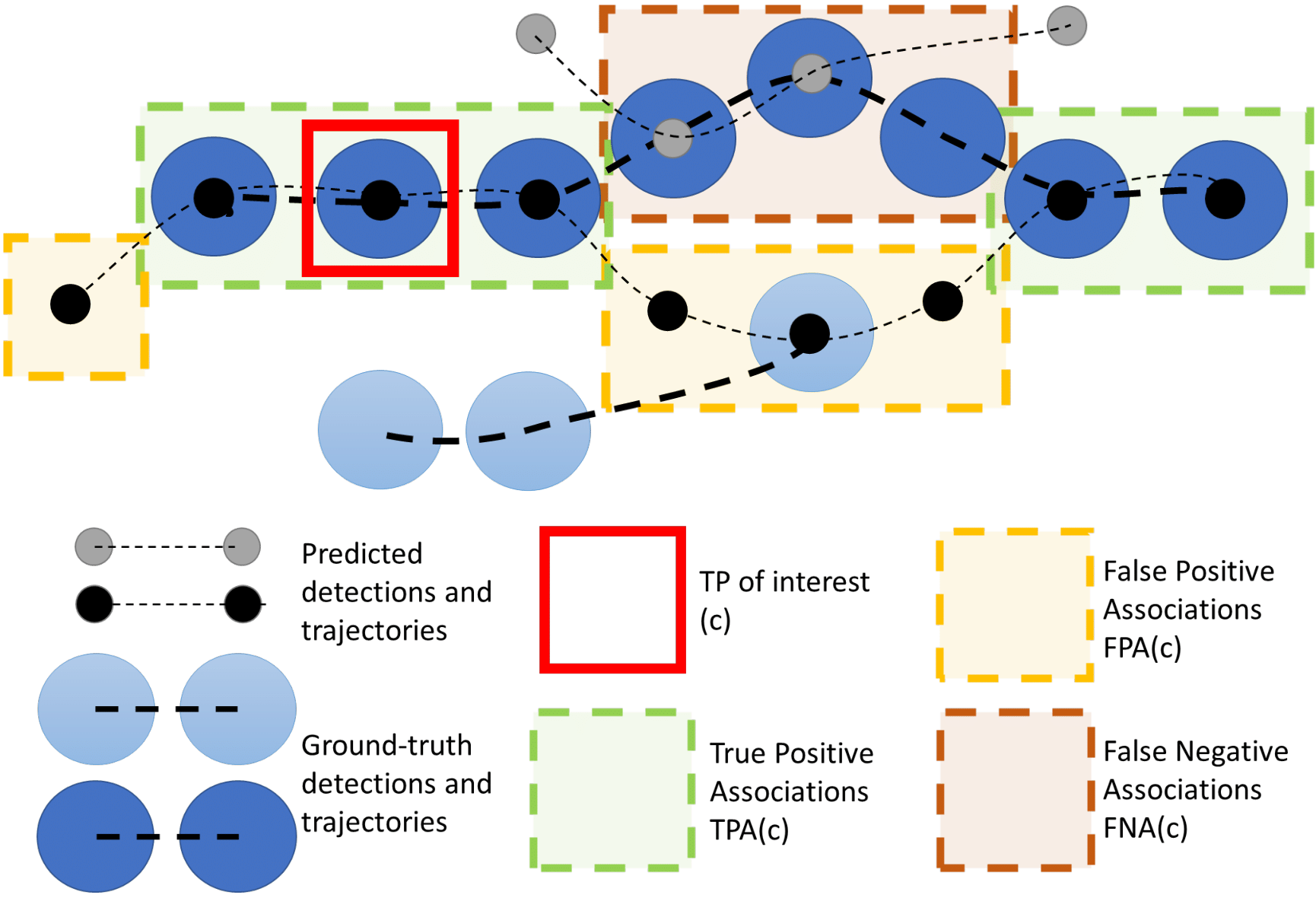
Multi-object tracking (MOT) has been notoriously difficult to evaluate. Previous metrics overemphasize the importance of either detection or association. To address this, we present a novel MOT evaluation metric, higher order tracking accuracy (HOTA), which explicitly balances the effect of performing accurate detection, association and localization into a single unified metric for comparing trackers. HOTA decomposes into a family of sub-metrics which are able to evaluate each of five basic error types separately, which enables clear analysis of tracking performance. We evaluate the effectiveness of HOTA on the MOTChallenge benchmark, and show that it is able to capture important aspects of MOT performance not previously taken into account by established metrics. Furthermore, we show HOTA scores better align with human visual evaluation of tracking performance.
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections

In interactive object segmentation a user collaborates with a computer vision model to segment an object. Recent works employ convolutional neural networks for this task: Given an image and a set of corrections made by the user as input, they output a segmentation mask. These approaches achieve strong performance by training on large datasets but they keep the model parameters unchanged at test time. Instead, we recognize that user corrections can serve as sparse training examples and we propose a method that capitalizes on that idea to update the model parameters on-the-fly to the data at hand. Our approach enables the adaptation to a particular object and its background, to distributions shifts in a test set, to specific object classes, and even to large domain changes, where the imaging modality changes between training and testing. We perform extensive experiments on 8 diverse datasets and show: Compared to a model with frozen parameters, our method reduces the required corrections (i) by 9%-30% when distribution shifts are small between training and testing; (ii) by 12%-44% when specializing to a specific class; (iii) and by 60% and 77% when we completely change domain between training and testing.
@inproceedings{Kontogianni20ECCV,
title={Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections},
author={ Kontogianni, Theodora and Gygli, Michael and Uijlings, Jasper and Ferrari, Vittorio},
booktitle=ECCV,
year={2020}
}
Higher-Order Finite Elements for Embedded Simulation
As demands for high-fidelity physics-based animations increase, the need for accurate methods for simulating deformable solids grows. While higher-order finite elements are commonplace in engineering due to their superior approximation properties for many problems, they have gained little traction in the computer graphics community. This may partially be explained by the need for finite element meshes to approximate the highly complex geometry of models used in graphics applications. Due to the additional per-element computational expense of higher-order elements, larger elements are needed, and the error incurred due to the geometry mismatch eradicates the benefits of higher-order discretizations. One solution to this problem is the embedding of the geometry into a coarser finite element mesh. However, to date there is no adequate, practical computational framework that permits the accurate embedding into higher-order elements.
We develop a novel, robust quadrature generation method that generates theoretically guaranteed high-quality sub-cell integration rules of arbitrary polynomial accuracy. The number of quadrature points generated is bounded only by the desired degree of the polynomial, independent of the embedded geometry. Additionally, we build on recent work in the Finite Cell Method (FCM) community so as to tackle the severe ill-conditioning caused by partially filled elements by adapting an Additive-Schwarz-based preconditioner so that it is suitable for use with state-of-the-art non-linear material models from the graphics literature. Together these two contributions constitute a general-purpose framework for embedded simulation with higher-order finite elements.
We finally demonstrate the benefits of our framework in several scenarios, in which second-order hexahedra and tetrahedra clearly outperform their first-order counterparts.
@ARTICLE{ LLKFB20,
author= {Andreas Longva and Fabian L{\"{o}}schner and Tassilo Kugelstadt and Jos{\'{e}} Antonio Fern{\'{a}}ndez-Fern{\'{a}}ndez and Jan Bender },
title= {{Higher-Order Finite Elements for Embedded Simulation}},
year= {2020},
journal= {ACM Transactions on Graphics (SIGGRAPH Asia)},
publisher= {ACM},
volume = {39},
number = {6},
pages= {14}
}
STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos

Existing methods for instance segmentation in videos typically involve multi-stage pipelines that follow the tracking-by-detection paradigm and model a video clip as a sequence of images. Multiple networks are used to detect objects in individual frames, and then associate these detections over time. Hence, these methods are often non-end-to-end trainable and highly tailored to specific tasks. In this paper, we propose a different approach that is well-suited to a variety of tasks involving instance segmentation in videos. In particular, we model a video clip as a single 3D spatio-temporal volume, and propose a novel approach that segments and tracks instances across space and time in a single stage. Our problem formulation is centered around the idea of spatio-temporal embeddings which are trained to cluster pixels belonging to a specific object instance over an entire video clip. To this end, we introduce (i) novel mixing functions that enhance the feature representation of spatio-temporal embeddings, and (ii) a single-stage, proposal-free network that can reason about temporal context. Our network is trained end-to-end to learn spatio-temporal embeddings as well as parameters required to cluster these embeddings, thus simplifying inference. Our method achieves state-of-the-art results across multiple datasets and tasks.
@inproceedings{AtharMahadevan20ECCV,
title={STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos},
author={Athar, Ali and Mahadevan, Sabarinath and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle=ECCV,
year={2020}
}
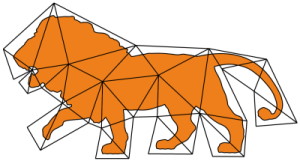
Inter-Surface Maps via Constant-Curvature Metrics
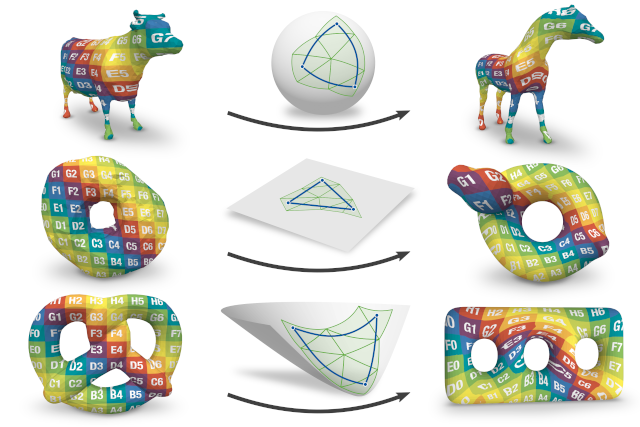
We propose a novel approach to represent maps between two discrete surfaces of the same genus and to minimize intrinsic mapping distortion. Our maps are well-defined at every surface point and are guaranteed to be continuous bijections (surface homeomorphisms). As a key feature of our approach, only the images of vertices need to be represented explicitly, since the images of all other points (on edges or in faces) are properly defined implicitly. This definition is via unique geodesics in metrics of constant Gaussian curvature. Our method is built upon the fact that such metrics exist on surfaces of arbitrary topology, without the need for any cuts or cones (as asserted by the uniformization theorem). Depending on the surfaces' genus, these metrics exhibit one of the three classical geometries: Euclidean, spherical or hyperbolic. Our formulation handles constructions in all three geometries in a unified way. In addition, by considering not only the vertex images but also the discrete metric as degrees of freedom, our formulation enables us to simultaneously optimize the images of these vertices and images of all other points.
@article{schmidt2020intersurface,
author = {Schmidt, Patrick and Campen, Marcel and Born, Janis and Kobbelt, Leif},
title = {Inter-Surface Maps via Constant-Curvature Metrics},
journal = {ACM Transactions on Graphics},
issue_date = {July 2020},
volume = {39},
number = {4},
month = jul,
year = {2020},
articleno = {119},
url = {https://doi.org/10.1145/3386569.3392399},
doi = {10.1145/3386569.3392399},
publisher = {ACM},
address = {New York, NY, USA},
}
3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation

We present 3D-MPA, a method for instance segmentation on 3D point clouds. Given an input point cloud, we propose an object-centric approach where each point votes for its object center. We sample object proposals from the predicted object centers. Then we learn proposal features from grouped point features that voted for the same object center. A graph convolutional network introduces inter-proposal relations, providing higher-level feature learning in addition to the lower-level point features. Each proposal comprises a semantic label, a set of associated points over which we define a foreground-background mask, an objectness score and aggregation features. Previous works usually perform non-maximum-suppression (NMS) over proposals to obtain the final object detections or semantic instances. However, NMS can discard potentially correct predictions. Instead, our approach keeps all proposals and groups them together based on the learned aggregation features. We show that grouping proposals improves over NMS and outperforms previous state-of-the-art methods on the tasks of 3D object detection and semantic instance segmentation on the ScanNetV2 benchmark and the S3DIS dataset.
@inproceedings{Engelmann20CVPR,
title = {{3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation}},
author = {Engelmann, Francis and Bokeloh, Martin and Fathi, Alireza and Leibe, Bastian and Nie{\ss}ner, Matthias},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2020}
}
DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes
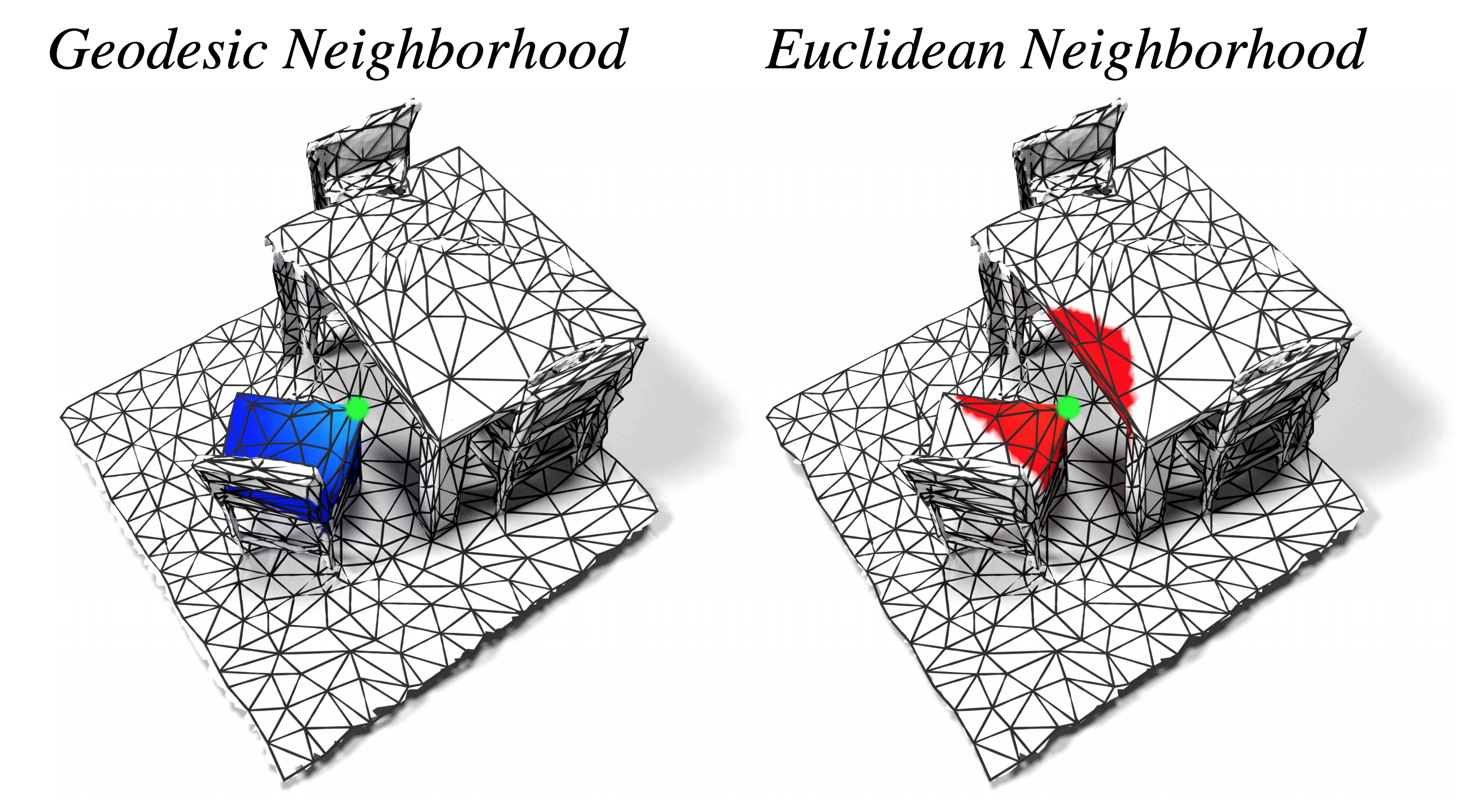
We propose DualConvMesh-Nets (DCM-Net) a family of deep hierarchical convolutional networks over 3D geometric data that combines two types of convolutions. The first type, geodesic convolutions, defines the kernel weights over mesh surfaces or graphs. That is, the convolutional kernel weights are mapped to the local surface of a given mesh. The second type, Euclidean convolutions, is independent of any underlying mesh structure. The convolutional kernel is applied on a neighborhood obtained from a local affinity representation based on the Euclidean distance between 3D points. Intuitively, geodesic convolutions can easily separate objects that are spatially close but have disconnected surfaces, while Euclidean convolutions can represent interactions between nearby objects better, as they are oblivious to object surfaces. To realize a multi-resolution architecture, we borrow well-established mesh simplification methods from the geometry processing domain and adapt them to define mesh-preserving pooling and unpooling operations. We experimentally show that combining both types of convolutions in our architecture leads to significant performance gains for 3D semantic segmentation, and we report competitive results on three scene segmentation benchmarks.
@inproceedings{Schult20CVPR,
author = {Jonas Schult* and
Francis Engelmann* and
Theodora Kontogianni and
Bastian Leibe},
title = {{DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes}},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2020}
}
Siam R-CNN: Visual Tracking by Re-Detection

We present Siam R-CNN, a Siamese re-detection architecture which unleashes the full power of two-stage object detection approaches for visual object tracking. We combine this with a novel tracklet-based dynamic programming algorithm, which takes advantage of re-detections of both the first-frame template and previous-frame predictions, to model the full history of both the object to be tracked and potential distractor objects. This enables our approach to make better tracking decisions, as well as to re-detect tracked objects after long occlusion. Finally, we propose a novel hard example mining strategy to improve Siam RCNN’s robustness to similar looking objects. The proposed tracker achieves the current best performance on ten tracking benchmarks, with especially strong results for long-term tracking.
@inproceedings{Voigtlaender20CVPR,
title={Siam R-CNN: Visual Tracking by Re-Detection},
author={Paul Voigtlaender and Jonathon Luiten and Philip H. S. Torr and Bastian Leibe},
year={2020},
booktitle={CVPR},
}
Making a Case for 3D Convolutions for Object Segmentation in Videos

The task of object segmentation in videos is usually accomplished by processing appearance and motion information separately using standard 2D convolutional networks, followed by a learned fusion of the two sources of information. On the other hand, 3D convolutional networks have been successfully applied for video classification tasks, but have not been leveraged as effectively to problems involving dense per-pixel interpretation of videos compared to their 2D convolutional counterparts and lag behind the aforementioned networks in terms of performance. In this work, we show that 3D CNNs can be effectively applied to dense video prediction tasks such as salient object segmentation. We propose a simple yet effective encoder-decoder network architecture consisting entirely of 3D convolutions that can be trained end-to-end using a standard cross-entropy loss. To this end, we leverage an efficient 3D encoder, and propose a 3D decoder architecture, that comprises novel 3D Global Convolution layers and 3D Refinement modules. Our approach outperforms existing state-of-the-arts by a large margin on the DAVIS'16 Unsupervised, FBMS and ViSal dataset benchmarks in addition to being faster, thus showing that our architecture can efficiently learn expressive spatio-temporal features and produce high quality video segmentation masks.
@inproceedings{Mahadevan20BMVC,
title={Making a Case for 3D Convolutions for Object Segmentation in Videos},
author={Mahadevan, Sabarinath and Athar, Ali and O{\v{s}}ep, Aljo{\v{s}}a and Hennen, Sebastian and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle={BMVC},
year={2020}
}
Implicit Frictional Boundary Handling for SPH

In this paper, we present a novel method for the robust handling of static and dynamic rigid boundaries in Smoothed Particle Hydrodynamics (SPH) simulations. We build upon the ideas of the density maps approach which has been introduced recently by Koschier and Bender. They precompute the density contributions of solid boundaries and store them on a spatial grid which can be efficiently queried during runtime. This alleviates the problems of commonly used boundary particles, like bumpy surfaces and inaccurate pressure forces near boundaries. Our method is based on a similar concept but we precompute the volume contribution of the boundary geometry. This maintains all benefits of density maps but offers a variety of advantages which are demonstrated in several experiments. Firstly, in contrast to the density maps method we can compute derivatives in the standard SPH manner by differentiating the kernel function. This results in smooth pressure forces, even for lower map resolutions, such that precomputation times and memory requirements are reduced by more than two orders of magnitude compared to density maps. Furthermore, this directly fits into the SPH concept so that volume maps can be seamlessly combined with existing SPH methods. Finally, the kernel function is not baked into the map such that the same volume map can be used with different kernels. This is especially useful when we want to incorporate common surface tension or viscosity methods that use different kernels than the fluid simulation.
@Article{BKWK2020,
author = {Jan Bender and Tassilo Kugelstadt and Marcel Weiler and Dan Koschier },
title = {Implicit Frictional Boundary Handling for SPH},
journal = {IEEE Transactions on Visualization and Computer Graphics},
year = {2020},
publisher = {IEEE},
volume={26},
number={10},
pages={2982-2993},
doi={10.1109/TVCG.2020.3004245},
}
Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds
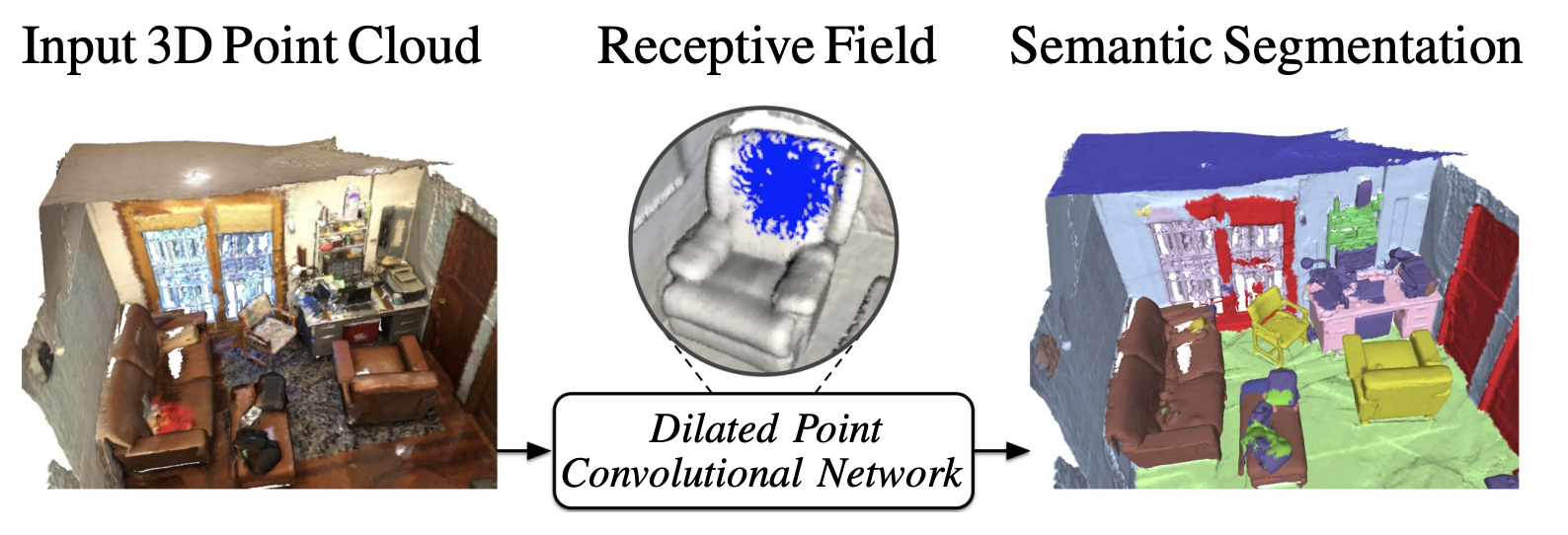
In this work, we propose Dilated Point Convolutions (DPC). In a thorough ablation study, we show that the receptive field size is directly related to the performance of 3D point cloud processing tasks, including semantic segmentation and object classification. Point convolutions are widely used to efficiently process 3D data representations such as point clouds or graphs. However, we observe that the receptive field size of recent point convolutional networks is inherently limited. Our dilated point convolutions alleviate this issue, they significantly increase the receptive field size of point convolutions. Importantly, our dilation mechanism can easily be integrated into most existing point convolutional networks. To evaluate the resulting network architectures, we visualize the receptive field and report competitive scores on popular point cloud benchmarks.
@inproceedings{Engelmann20ICRA,
author = {Engelmann, Francis and Kontogianni, Theodora and Leibe, Bastian},
title = {{Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds}},
booktitle = {{International Conference on Robotics and Automation (ICRA)}},
year = {2020}
}
Track to Reconstruct and Reconstruct to Track

Object tracking and 3D reconstruction are often performed together, with tracking used as input for reconstruction. However, the obtained reconstructions also provide useful information for improving tracking. We propose a novel method that closes this loop, first tracking to reconstruct, and then reconstructing to track. Our approach, MOTSFusion (Multi-Object Tracking, Segmentation and dynamic object Fusion), exploits the 3D motion extracted from dynamic object reconstructions to track objects through long periods of complete occlusion and to recover missing detections. Our approach first builds up short tracklets using 2D optical flow, and then fuses these into dynamic 3D object reconstructions. The precise 3D object motion of these reconstructions is used to merge tracklets through occlusion into long-term tracks, and to locate objects when detections are missing. On KITTI, our reconstruction-based tracking reduces the number of ID switches of the initial tracklets by more than 50%, and outperforms all previous approaches for both bounding box and segmentation tracking.
@article{luiten2020track,
title={Track to Reconstruct and Reconstruct to Track},
author={Luiten, Jonathon and Fischer, Tobias and Leibe, Bastian},
journal={IEEE Robotics and Automation Letters},
volume={5},
number={2},
pages={1803--1810},
year={2020},
publisher={IEEE}
}
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixel masks for salient objects in a video sequence and of tracking these objects consistently through time, without any input about which objects should be tracked. Towards solving this task, we present UnOVOST (Unsupervised Offline Video Object Segmentation and Tracking) as a simple and generic algorithm which is able to track and segment a large variety of objects. This algorithm builds up tracks in a number stages, first grouping segments into short tracklets that are spatio-temporally consistent, before merging these tracklets into long-term consistent object tracks based on their visual similarity. In order to achieve this we introduce a novel tracklet-based Forest Path Cutting data association algorithm which builds up a decision forest of track hypotheses before cutting this forest into paths that form long-term consistent object tracks. When evaluating our approach on the DAVIS 2017 Unsupervised dataset we obtain state-of-the-art performance with a mean J &F score of 67.9% on the val, 58% on the test-dev and 56.4% on the test-challenge benchmarks, obtaining first place in the DAVIS 2019 Unsupervised Video Object Segmentation Challenge. UnOVOST even performs competitively with many semi-supervised video object segmentation algorithms even though it is not given any input as to which objects should be tracked and segmented.
@inproceedings{luiten2020unovost,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking},
author={Luiten, Jonathon and Zulfikar, Idil Esen and Leibe, Bastian},
booktitle={Proceedings of the IEEE Winter Conference on Applications in Computer Vision},
year={2020}
}
Metric-Scale Truncation-Robust Heatmaps for 3D Human Pose Estimation
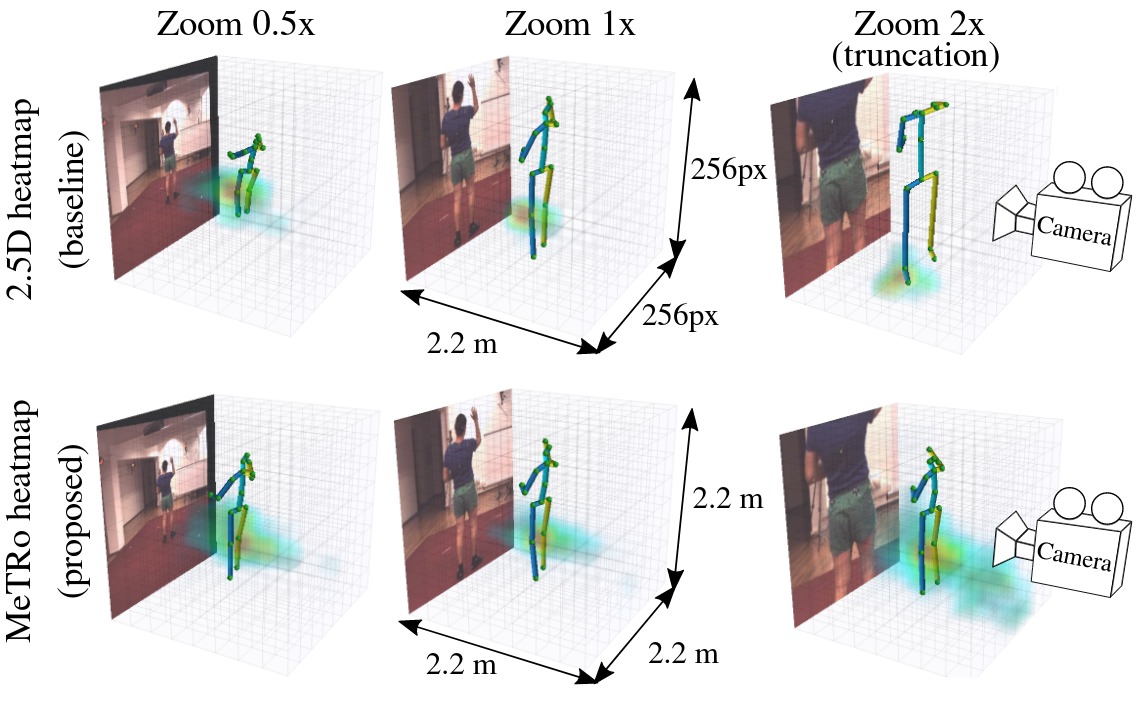
Heatmap representations have formed the basis of 2D human pose estimation systems for many years, but their generalizations for 3D pose have only recently been considered. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and the Z axis to metric depth around the subject. To obtain metric-scale predictions, these methods must include a separate, explicit post-processing step to resolve scale ambiguity. Further, they cannot encode body joint positions outside of the image boundaries, leading to incomplete pose estimates in case of image truncation. We address these limitations by proposing metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are defined in metric 3D space near the subject, instead of being aligned with image space. We train a fully-convolutional network to estimate such heatmaps from monocular RGB in an end-to-end manner. This reinterpretation of the heatmap dimensions allows us to estimate complete metric-scale poses without test-time knowledge of the focal length or person distance and without relying on anthropometric heuristics in post-processing. Furthermore, as the image space is decoupled from the heatmap space, the network can learn to reason about joints beyond the image boundary. Using ResNet-50 without any additional learned layers, we obtain state-of-the-art results on the Human3.6M and MPI-INF-3DHP benchmarks. As our method is simple and fast, it can become a useful component for real-time top-down multi-person pose estimation systems. We make our code publicly available to facilitate further research.
See also the extended journal version of this paper at https://vision.rwth-aachen.de/publication/00203 (journal version preferred for citation).
@inproceedings{Sarandi20metro,
title={Metric-Scale Truncation-Robust Heatmaps for {3D} Human Pose Estimation},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
booktitle={IEEE International Conference on Automatic Face and Gesture Recognition (FG)},
year={2020}
}
An Immersive Node-Link Visualization of Artificial Neural Networks for Machine Learning Experts
The black box problem of artificial neural networks (ANNs) is still a very relevant issue. When communicating basic concepts of ANNs, they are often depicted as node-link diagrams. Despite this being a straight forward way to visualize them, it is rarely used outside an educational context. However, we hypothesize that large-scale node-link diagrams of full ANNs could be useful even to machine learning experts. Hence, we present a visualization tool that depicts convolutional ANNs as node-link diagrams using immersive virtual reality. We applied our tool to a use-case in the field of machine learning research and adapted it to the specific challenges. Finally, we performed an expert review to evaluate the usefulness of our visualization. We found that our node-link visualization of ANNs was perceived as helpful in this professional context.
@inproceedings{Bellgardt2020a,
author = {Bellgardt, Martin and Scheiderer, Christian and Kuhlen, Torsten W.},
booktitle = {Proc. of IEEE AIVR}, title = {{An Immersive Node-Link Visualization of Artificial Neural Networks for Machine Learning Experts}},
year = {2020}
}
Higher-Order Time Integration for Deformable Solids

Visually appealing and vivid simulations of deformable solids represent an important aspect of physically based computer animation. For the temporal discretization, it is customary in computer animation to use first-order accurate integration methods, such as Backward Euler, due to their simplicity and robustness. Although there is notable research on second-order methods, their use is not widespread. Many of these well-known methods have significant drawbacks such as severe numerical damping or scene-dependent time step restrictions to ensure stability. In this paper, we discuss the most relevant requirements on such methods in computer animation and motivate the interest beyond first-order accuracy. Keeping these requirements in mind, we investigate several promising methods from the families of diagonally implicit Runge-Kutta (DIRK) and Rosenbrock methods which currently do not appear to have considerable popularity in this field. We show that the usage of such methods improves the visual quality of physical animations. In addition, we demonstrate that they allow distinctly more control over damping at lower computational cost than classical methods. As part of our theoretical contribution, we review aspects of simulations that are often considered more intricate with higher-order methods, such as contact handling. To this end, we derive an implicit linearized contact model based on a predictor-corrector approach that leads to consistent behavior with higher-order integrators as predictors. Our contact model is well suited for the simulation of stiff, nonlinear materials with the integration methods presented in this paper and more common methods such as Backward Euler alike.
@article{LLJKB20,
author = {Fabian L{\"{o}}schner and Andreas Longva and Stefan Jeske and Tassilo Kugelstadt and Jan Bender},
title = {Higher-Order Time Integration for Deformable Solids},
year = {2020},
journal = {Computer Graphics Forum},
volume = {39},
number = {8}
}
Inferring a User’s Intent on Joining or Passing by Social Groups

Modeling the interactions between users and social groups of virtual agents (VAs) is vital in many virtual-reality-based applications. However, only little research on group encounters has been conducted yet. We intend to close this gap by focusing on the distinction between joining and passing-by a group. To enhance the interactive capacity of VAs in these situations, knowing the user’s objective is required to showreasonable reactions. To this end,we propose a classification scheme which infers the user’s intent based on social cues such as proxemics, gazing and orientation, followed by triggering believable, non-verbal actions on the VAs.We tested our approach in a pilot study with overall promising results and discuss possible improvements for further studies.
@inproceedings{10.1145/3383652.3423862,
author = {B\"{o}nsch, Andrea and Bluhm, Alexander R. and Ehret, Jonathan and Kuhlen, Torsten W.},
title = {Inferring a User's Intent on Joining or Passing by Social Groups},
year = {2020},
isbn = {9781450375863},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3383652.3423862},
doi = {10.1145/3383652.3423862},
abstract = {Modeling the interactions between users and social groups of virtual agents (VAs) is vital in many virtual-reality-based applications. However, only little research on group encounters has been conducted yet. We intend to close this gap by focusing on the distinction between joining and passing-by a group. To enhance the interactive capacity of VAs in these situations, knowing the user's objective is required to show reasonable reactions. To this end, we propose a classification scheme which infers the user's intent based on social cues such as proxemics, gazing and orientation, followed by triggering believable, non-verbal actions on the VAs. We tested our approach in a pilot study with overall promising results and discuss possible improvements for further studies.},
booktitle = {Proceedings of the 20th ACM International Conference on Intelligent Virtual Agents},
articleno = {10},
numpages = {8},
keywords = {virtual agents, joining a group, social groups, virtual reality},
location = {Virtual Event, Scotland, UK},
series = {IVA '20}
}
Evaluating the Influence of Phoneme-Dependent Dynamic Speaker Directivity of Embodied Conversational Agents’ Speech
Generating natural embodied conversational agents within virtual spaces crucially depends on speech sounds and their directionality. In this work, we simulated directional filters to not only add directionality, but also directionally adapt each phoneme. We therefore mimic reality where changing mouth shapes have an influence on the directional propagation of sound. We conducted a study (n = 32) evaluating naturalism ratings, preference and distinguishability of omnidirectional speech auralization compared to static and dynamic, phoneme-dependent directivities. The results indicated that participants cannot distinguish dynamic from static directivity. Furthermore, participants’ preference ratings aligned with their naturalism ratings. There was no unanimity, however, with regards to which auralization is the most natural.
@inproceedings{10.1145/3383652.3423863,
author = {Ehret, Jonathan and Stienen, Jonas and Brozdowski, Chris and B\"{o}nsch, Andrea and Mittelberg, Irene and Vorl\"{a}nder, Michael and Kuhlen, Torsten W.},
title = {Evaluating the Influence of Phoneme-Dependent Dynamic Speaker Directivity of Embodied Conversational Agents' Speech},
year = {2020},
isbn = {9781450375863},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3383652.3423863},
doi = {10.1145/3383652.3423863},
abstract = {Generating natural embodied conversational agents within virtual spaces crucially depends on speech sounds and their directionality. In this work, we simulated directional filters to not only add directionality, but also directionally adapt each phoneme. We therefore mimic reality where changing mouth shapes have an influence on the directional propagation of sound. We conducted a study (n = 32) evaluating naturalism ratings, preference and distinguishability of omnidirectional speech auralization compared to static and dynamic, phoneme-dependent directivities. The results indicated that participants cannot distinguish dynamic from static directivity. Furthermore, participants' preference ratings aligned with their naturalism ratings. There was no unanimity, however, with regards to which auralization is the most natural.},
booktitle = {Proceedings of the 20th ACM International Conference on Intelligent Virtual Agents},
articleno = {17},
numpages = {8},
keywords = {phoneme-dependent directivity, directional 3D sound, speech, embodied conversational agents, virtual acoustics},
location = {Virtual Event, Scotland, UK},
series = {IVA '20}
}
Rilievo: Artistic Scene Authoring via Interactive Height Map Extrusion in VR

The authors present a virtual authoring environment for artistic creation in VR. It enables the effortless conversion of 2D images into volumetric 3D objects. Artistic elements in the input material are extracted with a convenient VR-based segmentation tool. Relief sculpting is then performed by interactively mixing different height maps. These are automatically generated from the input image structure and appearance. A prototype of the tool is showcased in an analog-virtual artistic workflow in collaboration with a traditional painter. It combines the expressiveness of analog painting and sculpting with the creative freedom of spatial arrangement in VR.
@article{eroglu2020rilievo,
title={Rilievo: Artistic Scene Authoring via Interactive Height Map Extrusion in VR},
author={Eroglu, Sevinc and Schmitz, Patric and Martinez, Carlos Aguilera and Rusch, Jana and Kobbelt, Leif and Kuhlen, Torsten W},
journal={Leonardo},
volume={53},
number={4},
pages={438--441},
year={2020},
publisher={MIT Press}
}
Fast and Robust QEF Minimization using Probabilistic Quadrics

Error quadrics are a fundamental and powerful building block in many geometry processing algorithms. However, finding the minimizer of a given quadric is in many cases not robust and requires a singular value decomposition or some ad-hoc regularization. While classical error quadrics measure the squared deviation from a set of ground truth planes or polygons, we treat the input data as genuinely uncertain information and embed error quadrics in a probabilistic setting ("probabilistic quadrics") where the optimal point minimizes the expected squared error. We derive closed form solutions for the popular plane and triangle quadrics subject to (spatially varying, anisotropic) Gaussian noise. Probabilistic quadrics can be minimized robustly by solving a simple linear system - 50x faster than SVD. We show that probabilistic quadrics have superior properties in tasks like decimation and isosurface extraction since they favor more uniform triangulations and are more tolerant to noise while still maintaining feature sensitivity. A broad spectrum of applications can directly benefit from our new quadrics as a drop-in replacement which we demonstrate with mesh smoothing via filtered quadrics and non-linear subdivision surfaces.
@article {10.1111:cgf.13933,
journal = {Computer Graphics Forum},
title = {{Fast and Robust QEF Minimization using Probabilistic Quadrics}},
author = {Trettner, Philip and Kobbelt, Leif},
year = {2020},
publisher = {The Eurographics Association and John Wiley & Sons Ltd.},
ISSN = {1467-8659},
DOI = {10.1111/cgf.13933}
}
High-Fidelity Point-Based Rendering of Large-Scale 3D Scan Datasets

Digitalization of 3D objects and scenes using modern depth sensors and high-resolution RGB cameras enables the preservation of human cultural artifacts at an unprecedented level of detail. Interactive visualization of these large datasets, however, is challenging without degradation in visual fidelity. A common solution is to fit the dataset into available video memory by downsampling and compression. The achievable reproduction accuracy is thereby limited for interactive scenarios, such as immersive exploration in Virtual Reality (VR). This degradation in visual realism ultimately hinders the effective communication of human cultural knowledge. This article presents a method to render 3D scan datasets with minimal loss of visual fidelity. A point-based rendering approach visualizes scan data as a dense splat cloud. For improved surface approximation of thin and sparsely sampled objects, we propose oriented 3D ellipsoids as rendering primitives. To render massive texture datasets, we present a virtual texturing system that dynamically loads required image data. It is paired with a single-pass page prediction method that minimizes visible texturing artifacts. Our system renders a challenging dataset in the order of 70 million points and a texture size of 1.2 terabytes consistently at 90 frames per second in stereoscopic VR.
Feature Tracking by Two-Step Optimization
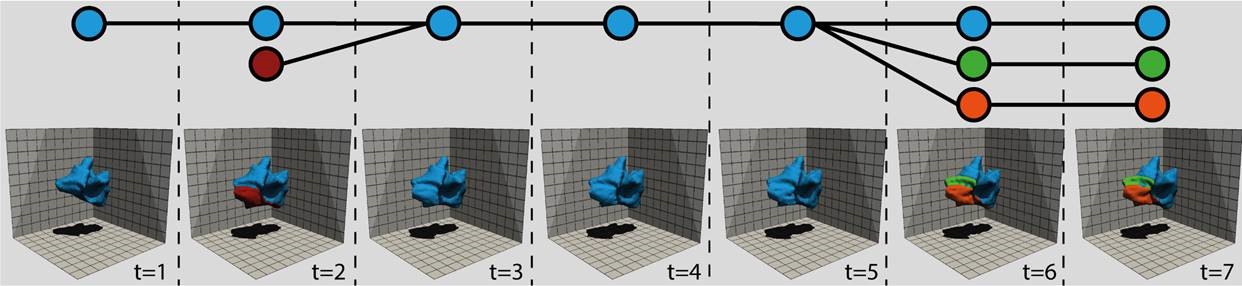
Tracking the temporal evolution of features in time-varying data is a key method in visualization. For typical feature definitions, such as vortices, objects are sparsely distributed over the data domain. In this paper, we present a novel approach for tracking both sparse and space-filling features. While the former comprise only a small fraction of the domain, the latter form a set of objects whose union covers the domain entirely while the individual objects are mutually disjunct. Our approach determines the assignment of features between two successive time-steps by solving two graph optimization problems. It first resolves one-to-one assignments of features by computing a maximum-weight, maximum-cardinality matching on a weighted bi-partite graph. Second, our algorithm detects events by creating a graph of potentially conflicting event explanations and finding a weighted, independent set in it. We demonstrate our method's effectiveness on synthetic and simulation data sets, the former of which enables quantitative evaluation because of the availability of ground-truth information. Here, our method performs on par or better than a well-established reference algorithm. In addition, manual visual inspection by our collaborators confirm the results' plausibility for simulation data.
@ARTICLE{Schnorr2018,
author = {Andrea Schnorr and Dirk N. Helmrich and Dominik Denker and Torsten W. Kuhlen and Bernd Hentschel},
title = {{F}eature {T}racking by {T}wo-{S}tep {O}ptimization},
journal = TVCG,
volume = {preprint available online},
doi = {https://doi.org/10.1109/TVCG.2018.2883630},
year = 2018,
}
The Impact of a Virtual Agent’s Non-Verbal Emotional Expression on a User’s Personal Space Preferences

Virtual-reality-based interactions with virtual agents (VAs) are likely subject to similar influences as human-human interactions. In either real or virtual social interactions, interactants try to maintain their personal space (PS), an ubiquitous, situative, flexible safety zone. Building upon larger PS preferences to humans and VAs with angry facial expressions, we extend the investigations to whole-body emotional expressions. In two immersive settings–HMD and CAVE–66 males were approached by an either happy, angry, or neutral male VA. Subjects preferred a larger PS to the angry VA when being able to stop him at their convenience (Sample task), replicating previous findings, and when being able to actively avoid him (PassBy task). In the latter task, we also observed larger distances in the CAVE than in the HMD.
@inproceedings{10.1145/3383652.3423888,
author = {B\"{o}nsch, Andrea and Radke, Sina and Ehret, Jonathan and Habel, Ute and Kuhlen, Torsten W.},
title = {The Impact of a Virtual Agent's Non-Verbal Emotional Expression on a User's Personal Space Preferences},
year = {2020},
isbn = {9781450375863},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3383652.3423888},
doi = {10.1145/3383652.3423888},
abstract = {Virtual-reality-based interactions with virtual agents (VAs) are likely subject to similar influences as human-human interactions. In either real or virtual social interactions, interactants try to maintain their personal space (PS), an ubiquitous, situative, flexible safety zone. Building upon larger PS preferences to humans and VAs with angry facial expressions, we extend the investigations to whole-body emotional expressions. In two immersive settings-HMD and CAVE-66 males were approached by an either happy, angry, or neutral male VA. Subjects preferred a larger PS to the angry VA when being able to stop him at their convenience (Sample task), replicating previous findings, and when being able to actively avoid him (Pass By task). In the latter task, we also observed larger distances in the CAVE than in the HMD.},
booktitle = {Proceedings of the 20th ACM International Conference on Intelligent Virtual Agents},
articleno = {12},
numpages = {8},
keywords = {personal space, virtual reality, emotions, virtual agents},
location = {Virtual Event, Scotland, UK},
series = {IVA '20}
}
The 19 Unifying Questionnaire Constructs of Artificial Social Agents: An IVA Community Analysis
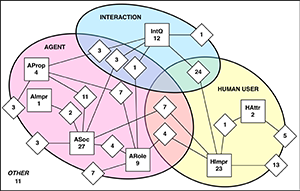
In this paper, we report on the multi-year Intelligent Virtual Agents (IVA) community effort, involving more than 80 researchers worldwide, researching the IVA community interests and practises in evaluating human interaction with an artificial social agent (ASA). The effort is driven by previous IVA workshops and plenary IVA discussions related to the methodological crisis on the evaluation of ASAs. A previous literature review showed a continuous practise of creating new questionnaires instead of reusing validated questionnaires. We address this issue by examining questionnaire measurement constructs used in empirical studies between 2013 to 2018 published in the IVA conference. We identified 189 constructs used in 89 questionnaires that are reported across 81 studies. Although these constructs have different names, they often measure the same thing. In this paper, we, therefore, present a unifying set of 19 constructs that captures more than 80% of the 189 constructs initially identified. We established this set in two steps. First, 49 researchers classified the constructs in broad theoretically based categories. Next, 23 researchers grouped the constructs in each category on their similarity. The resulting 19 groups form a unifying set of constructs, which will be the basis for the future questionnaire instrument of human-ASA interaction.
Nominated for the Best Paper Award.
@inproceedings{10.1145/3383652.3423873,
author = {Fitrianie, Siska and Bruijnes, Merijn and Richards, Deborah and B\"{o}nsch, Andrea and Brinkman, Willem-Paul},
title = {The 19 Unifying Questionnaire Constructs of Artificial Social Agents: An IVA Community Analysis},
year = {2020},
isbn = {9781450375863},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3383652.3423873},
doi = {10.1145/3383652.3423873},
abstract = {In this paper, we report on the multi-year Intelligent Virtual Agents (IVA) community effort, involving more than 80 researchers worldwide, researching the IVA community interests and practises in evaluating human interaction with an artificial social agent (ASA). The effort is driven by previous IVA workshops and plenary IVA discussions related to the methodological crisis on the evaluation of ASAs. A previous literature review showed a continuous practise of creating new questionnaires instead of reusing validated questionnaires. We address this issue by examining questionnaire measurement constructs used in empirical studies between 2013 to 2018 published in the IVA conference. We identified 189 constructs used in 89 questionnaires that are reported across 81 studies. Although these constructs have different names, they often measure the same thing. In this paper, we, therefore, present a unifying set of 19 constructs that captures more than 80% of the 189 constructs initially identified. We established this set in two steps. First, 49 researchers classified the constructs in broad theoretically based categories. Next, 23 researchers grouped the constructs in each category on their similarity. The resulting 19 groups form a unifying set of constructs, which will be the basis for the future questionnaire instrument of human-ASA interaction.},
booktitle = {Proceedings of the 20th ACM International Conference on Intelligent Virtual Agents},
articleno = {21},
numpages = {8},
keywords = {evaluation instrument, user study, Artificial social agent, questionnaire, measurement construct},
location = {Virtual Event, Scotland, UK},
series = {IVA '20}
}
High-Performance Image Filters via Sparse Approximations

We present a numerical optimization method to find highly efficient (sparse) approximations for convolutional image filters. Using a modified parallel tempering approach, we solve a constrained optimization that maximizes approximation quality while strictly staying within a user-prescribed performance budget. The results are multi-pass filters where each pass computes a weighted sum of bilinearly interpolated sparse image samples, exploiting hardware acceleration on the GPU. We systematically decompose the target filter into a series of sparse convolutions, trying to find good trade-offs between approximation quality and performance. Since our sparse filters are linear and translation-invariant, they do not exhibit the aliasing and temporal coherence issues that often appear in filters working on image pyramids. We show several applications, ranging from simple Gaussian or box blurs to the emulation of sophisticated Bokeh effects with user-provided masks. Our filters achieve high performance as well as high quality, often providing significant speed-up at acceptable quality even for separable filters. The optimized filters can be baked into shaders and used as a drop-in replacement for filtering tasks in image processing or rendering pipelines.
Cost Minimizing Local Anisotropic Quad Mesh Refinement

Quad meshes as a surface representation have many conceptual advantages over triangle meshes. Their edges can naturally be aligned to principal curvatures of the underlying surface and they have the flexibility to create strongly anisotropic cells without causing excessively small inner angles. While in recent years a lot of progress has been made towards generating high quality uniform quad meshes for arbitrary shapes, their adaptive and anisotropic refinement remains difficult since a single edge split might propagate across the entire surface in order to maintain consistency. In this paper we present a novel refinement technique which finds the optimal trade-off between number of resulting elements and inserted singularities according to a user prescribed weighting. Our algorithm takes as input a quad mesh with those edges tagged that are prescribed to be refined. It then formulates a binary optimization problem that minimizes the number of additional edges which need to be split in order to maintain consistency. Valence 3 and 5 singularities have to be introduced in the transition region between refined and unrefined regions of the mesh. The optimization hence computes the optimal trade-off and places singularities strategically in order to minimize the number of consistency splits — or avoids singularities where this causes only a small number of additional splits. When applying the refinement scheme iteratively, we extend our binary optimization formulation such that previous splits can be undone if this prevents degenerate cells with small inner angles that otherwise might occur in anisotropic regions or in the vicinity of singularities. We demonstrate on a number of challenging examples that the algorithm performs well in practice.
@article{Lyon:2020:Cost,
title = {Cost Minimizing Local Anisotropic Quad Mesh Refinement},
author = {Lyon, Max and Bommes, David and Kobbelt, Leif},
journal = {Computer Graphics Forum},
volume = {39},
number = {5},
year = {2020},
doi = {10.1111/cgf.14076}
}
A Three-Level Approach to Texture Mapping and Synthesis on 3D Surfaces

We present a method for example-based texturing of triangular 3D meshes. Our algorithm maps a small 2D texture sample onto objects of arbitrary size in a seamless fashion, with no visible repetitions and low overall distortion. It requires minimal user interaction and can be applied to complex, multi-layered input materials that are not required to be tileable. Our framework integrates a patch-based approach with per-pixel compositing. To minimize visual artifacts, we run a three-level optimization that starts with a rigid alignment of texture patches (macro scale), then continues with non-rigid adjustments (meso scale) and finally performs pixel-level texture blending (micro scale). We demonstrate that the relevance of the three levels depends on the texture content and type (stochastic, structured, or anisotropic textures).
@article{schuster2020,
author = {Schuster, Kersten and Trettner, Philip and Schmitz, Patric and Kobbelt, Leif},
title = {A Three-Level Approach to Texture Mapping and Synthesis on 3D Surfaces},
year = {2020},
issue_date = {Apr 2020},
publisher = {The Association for Computers in Mathematics and Science Teaching},
address = {USA},
volume = {3},
number = {1},
url = {https://doi.org/10.1145/3384542},
doi = {10.1145/3384542},
journal = {Proc. ACM Comput. Graph. Interact. Tech.},
month = apr,
articleno = {1},
numpages = {19},
keywords = {material blending, surface texture synthesis, texture mapping}
}
PRS-Net: Planar Reflective Symmetry Detection Net for 3D Models
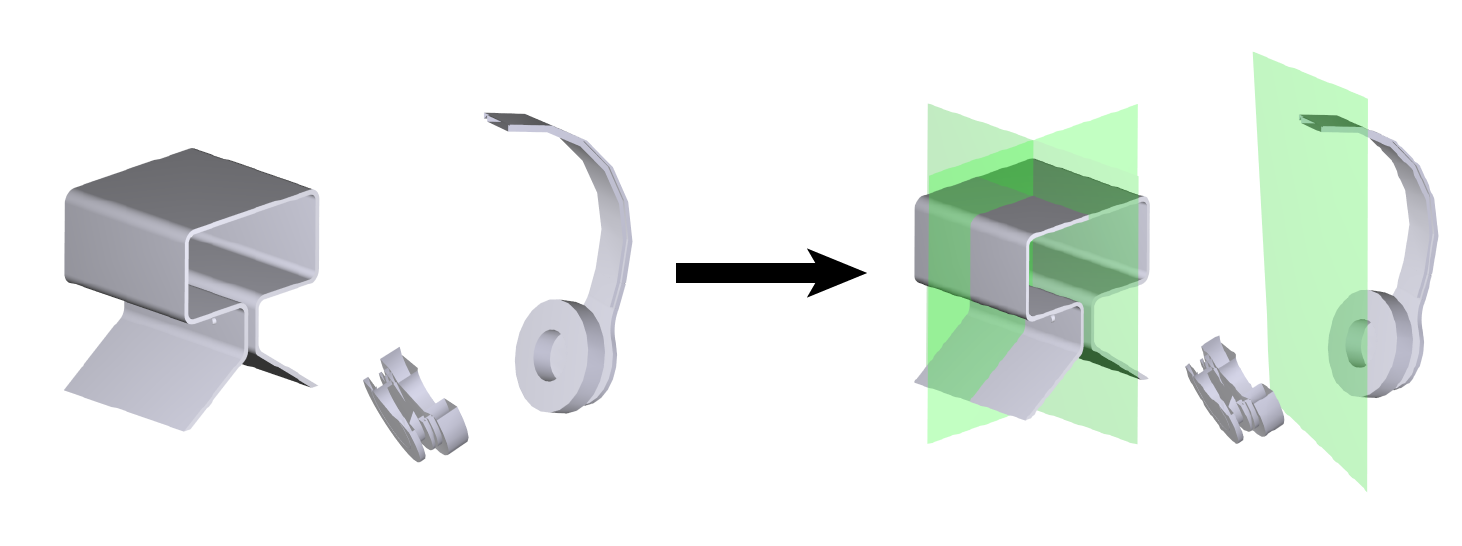
In geometry processing, symmetry is a universal type of high-level structural information of 3D models and benefits many geometry processing tasks including shape segmentation, alignment, matching, and completion. Thus it is an important problem to analyze various symmetry forms of 3D shapes. Planar reflective symmetry is the most fundamental one. Traditional methods based on spatial sampling can be time-consuming and may not be able to identify all the symmetry planes. In this paper, we present a novel learning framework to automatically discover global planar reflective symmetry of a 3D shape. Our framework trains an unsupervised 3D convolutional neural network to extract global model features and then outputs possible global symmetry parameters, where input shapes are represented using voxels. We introduce a dedicated symmetry distance loss along with a regularization loss to avoid generating duplicated symmetry planes. Our network can also identify generalized cylinders by predicting their rotation axes. We further provide a method to remove invalid and duplicated planes and axes. We demonstrate that our method is able to produce reliable and accurate results. Our neural network based method is hundreds of times faster than the state-of-the-art methods, which are based on sampling. Our method is also robust even with noisy or incomplete input surfaces.
@article{abs-1910-06511,
author = {Lin Gao and
Ling{-}Xiao Zhang and
Hsien{-}Yu Meng and
Yi{-}Hui Ren and
Yu{-}Kun Lai and
Leif Kobbelt},
title = {PRS-Net: Planar Reflective Symmetry Detection Net for 3D Models},
journal = {CoRR},
volume = {abs/1910.06511},
year = {2019},
url = {http://arxiv.org/abs/1910.06511},
archivePrefix = {arXiv},
eprint = {1910.06511},
}
Immersive Sketching to Author Crowd Movements in Real-time

the flow of virtual crowds in a direct and interactive manner. Here, options to redirect a flow by sketching barriers, or guiding entities based on a sketched network of connected sections are provided. As virtual crowds are increasingly often embedded into virtual reality (VR) applications, 3D authoring is of interest.
In this preliminary work, we thus present a sketch-based approach for VR. First promising results of a proof-of-concept are summarized and improvement suggestions, extensions, and future steps are discussed.
@inproceedings{10.1145/3383652.3423883,
author = {B\"{o}nsch, Andrea and Barton, Sebastian J. and Ehret, Jonathan and Kuhlen, Torsten W.},
title = {Immersive Sketching to Author Crowd Movements in Real-Time},
year = {2020},
isbn = {9781450375863},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3383652.3423883},
doi = {10.1145/3383652.3423883},
abstract = {Sketch-based interfaces in 2D screen space allow to efficiently author the flow of virtual crowds in a direct and interactive manner. Here, options to redirect a flow by sketching barriers, or guiding entities based on a sketched network of connected sections are provided.As virtual crowds are increasingly often embedded into virtual reality (VR) applications, 3D authoring is of interest. In this preliminary work, we thus present a sketch-based approach for VR. First promising results of a proof-of-concept are summarized and improvement suggestions, extensions, and future steps are discussed.},
booktitle = {Proceedings of the 20th ACM International Conference on Intelligent Virtual Agents},
articleno = {11},
numpages = {3},
keywords = {virtual crowds, virtual reality, sketch-based interface, authoring},
location = {Virtual Event, Scotland, UK},
series = {IVA '20}
}
Unsupervised Segmentation of Indoor 3D Point Cloud: Application to Object-based Classification
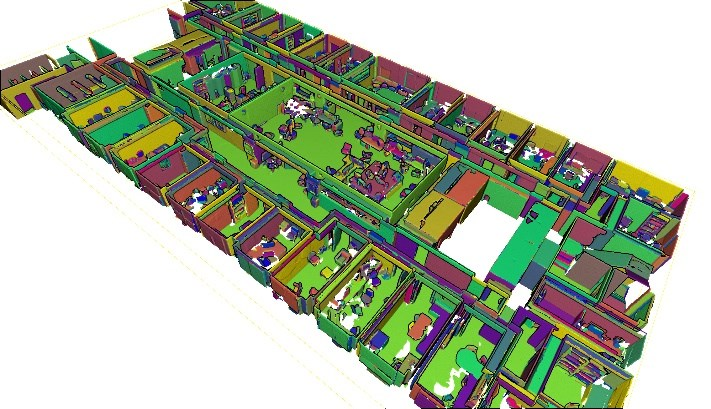
Point cloud data of indoor scenes is primarily composed of planar-dominant elements. Automatic shape segmentation is thus valuable to avoid labour intensive labelling. This paper provides a fully unsupervised region growing segmentation approach for efficient clustering of massive 3D point clouds. Our contribution targets a low-level grouping beneficial to object-based classification. We argue that the use of relevant segments for object-based classification has the potential to perform better in terms of recognition accuracy, computing time and lowers the manual labelling time needed. However, fully unsupervised approaches are rare due to a lack of proper generalisation of user-defined parameters. We propose a self-learning heuristic process to define optimal parameters, and we validate our method on a large and richly annotated dataset (S3DIS) yielding 88.1% average F1-score for object-based classification. It permits to automatically segment indoor point clouds with no prior knowledge at commercially viable performance and is the foundation for efficient indoor 3D modelling in cluttered point clouds.
@Article{poux2020b,
author = {Poux, F. and Mattes, C. and Kobbelt, L.},
title = {UNSUPERVISED SEGMENTATION OF INDOOR 3D POINT CLOUD: APPLICATION TO OBJECT-BASED CLASSIFICATION},
journal = {ISPRS - International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences},
volume = {XLIV-4/W1-2020},
year = {2020},
pages = {111--118},
url = {https://www.int-arch-photogramm-remote-sens-spatial-inf-sci.net/XLIV-4-W1-2020/111/2020/},
doi = {10.5194/isprs-archives-XLIV-4-W1-2020-111-2020}
}
Initial User-Centered Design of a Virtual Reality Heritage System: Applications for Digital Tourism

Reality capture allows for the reconstruction, with a high accuracy, of the physical reality of cultural heritage sites. Obtained 3D models are often used for various applications such as promotional content creation, virtual tours, and immersive experiences. In this paper, we study new ways to interact with these high-quality 3D reconstructions in a real-world scenario. We propose a user-centric product design to create a virtual reality (VR) application specifically intended for multi-modal purposes. It is applied to the castle of Jehay (Belgium), which is under renovation, to permit multi-user digital immersive experiences. The article proposes a high-level view of multi-disciplinary processes, from a needs analysis to the 3D reality capture workflow and the creation of a VR environment incorporated into an immersive application. We provide several relevant VR parameters for the scene optimization, the locomotion system, and the multi-user environment definition that were tested in a heritage tourism context.
@article{poux2020a,
title={Initial User-Centered Design of a Virtual Reality Heritage System: Applications for Digital Tourism},
volume={12},
ISSN={2072-4292},
url={http://dx.doi.org/10.3390/rs12162583},
DOI={10.3390/rs12162583},
number={16},
journal={Remote Sensing},
publisher={MDPI AG},
author={Poux, Florent and Valembois, Quentin and Mattes, Christian and Kobbelt, Leif and Billen, Roland},
year={2020},
month={Aug},
pages={2583}
}
Reposing Humans by Warping 3D Features
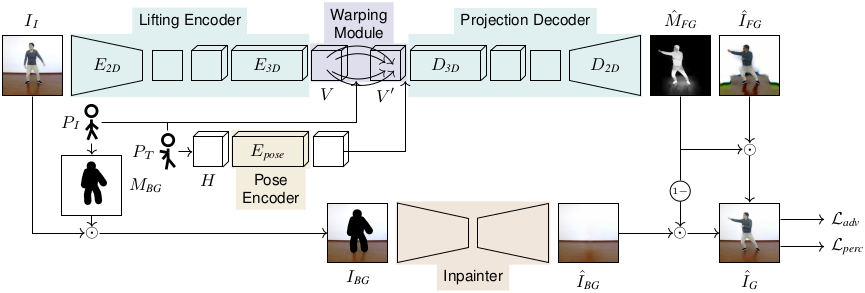
We address the problem of reposing an image of a human into any desired novel pose. This conditional image-generation task requires reasoning about the 3D structure of the human, including self-occluded body parts. Most prior works are either based on 2D representations or require fitting and manipulating an explicit 3D body mesh. Based on the recent success in deep learning-based volumetric representations, we propose to implicitly learn a dense feature volume from human images, which lends itself to simple and intuitive manipulation through explicit geometric warping. Once the latent feature volume is warped according to the desired pose change, the volume is mapped back to RGB space by a convolutional decoder. Our state-of-the-art results on the DeepFashion and the iPER benchmarks indicate that dense volumetric human representations are worth investigating in more detail.
@inproceedings{Knoche20reposing,
author = {Markus Knoche and Istv\'an S\'ar\'andi and Bastian Leibe},
title = {Reposing Humans by Warping {3D} Features},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
year = {2020}
}
Calibratio - A Small, Low-Cost, Fully Automated Motion-to-Photon Measurement Device

Since the beginning of the design and implementation of virtual environments, these systems have been built to give the users the best possible experience. One detrimental factor for the user experience was shown to be a high end-to-end latency, here measured as motionto-photon latency, of the system. Thus, a lot of research in the past was focused on the measurement and minimization of this latency in virtual environments. Most existing measurement-techniques require either expensive measurement hardware like an oscilloscope, mechanical components like a pendulum or depend on manual evaluation of samples. This paper proposes a concept of an easy to build, low-cost device consisting of a microcontroller, servo motor and a photo diode to measure the motion-to-photon latency in virtual reality environments fully automatically. It is placed or attached to the system, calibrates itself and is controlled/monitored via a web interface. While the general concept is applicable to a variety of VR technologies, this paper focuses on the context of CAVE-like systems.
@InProceedings{Pape2020a,
author = {Sebastian Pape and Marcel Kr\"{u}ger and Jan M\"{u}ller and Torsten W. Kuhlen},
title = {{Calibratio - A Small, Low-Cost, Fully Automated Motion-to-Photon Measurement Device}},
booktitle = {10th Workshop on Software Engineering and Architectures for Realtime Interactive Systems (SEARIS)},
year = {2020},
month={March}
}
Single-Shot Panoptic Segmentation
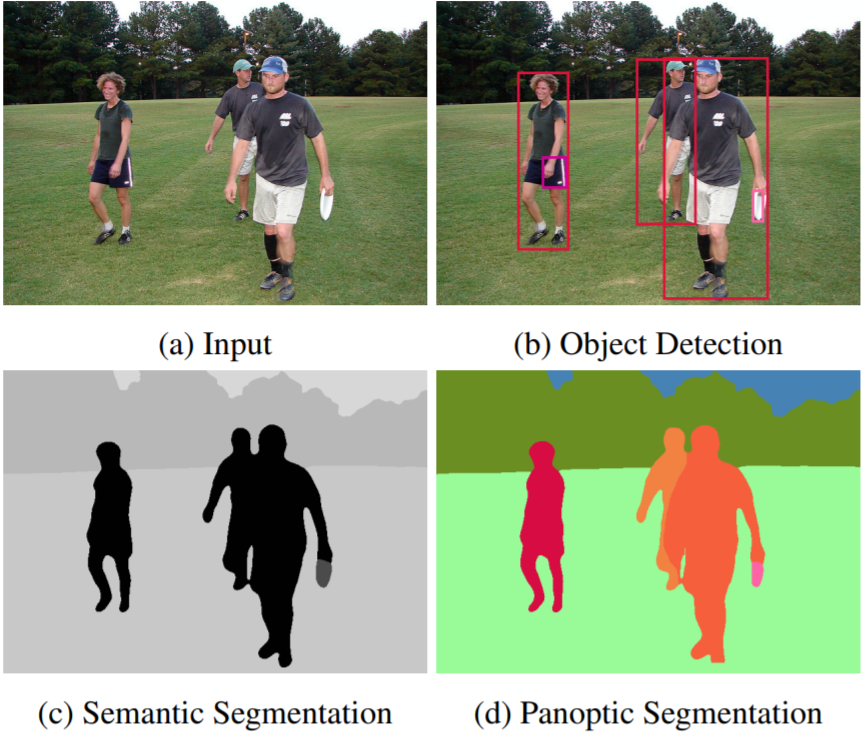
We present a novel end-to-end single-shot method that segments countable object instances (things) as well as background regions (stuff) into a non-overlapping panoptic segmentation at almost video frame rate. Current state-of-the-art methods are far from reaching video frame rate and mostly rely on merging instance segmentation with semantic background segmentation. Our approach relaxes this requirement by using an object detector but is still able to resolve inter- and intra-class overlaps to achieve a non-overlapping segmentation. On top of a shared encoder-decoder backbone, we utilize multiple branches for semantic segmentation, object detection, and instance center prediction. Finally, our panoptic head combines all outputs into a panoptic segmentation and can even handle conflicting predictions between branches as well as certain false predictions. Our network achieves 32.6% PQ on MS-COCO at 21.8 FPS, opening up panoptic segmentation to a broader field of applications.
@article{weber2019single,
title={Single-Shot Panoptic Segmentation},
author={Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
journal={arXiv preprint arXiv:1911.00764},
year={2019}
}
Joint Dual-Tasking in VR: Outlining the Behavioral Design of Interactive Human Companions Who Walk and Talk with a User

To resemble realistic and lively places, virtual environments are increasingly often enriched by virtual populations consisting of computer-controlled, human-like virtual agents. While the applications often provide limited user-agent interaction based on, e.g., collision avoidance or mutual gaze, complex user-agent dynamics such as joint locomotion combined with a secondary task, e.g., conversing, are rarely considered yet. These dual-tasking situations, however, are beneficial for various use-cases: guided tours and social simulations will become more realistic and engaging if a user is able to traverse a scene as a member of a social group, while platforms to study crowd and walking behavior will become more powerful and informative. To this end, this presentation deals with different areas of interaction dynamics, which need to be combined for modeling dual-tasking with virtual agents. Areas covered are kinematic parameters for the navigation behavior, group shapes in static and mobile situations as well as verbal and non-verbal behavior for conversations.
@InProceedings{Boensch2020a,
author = {Andrea B\"{o}nsch and Torsten W. Kuhlen},
title = {{Joint Dual-Tasking in VR: Outlining the Behavioral Design of Interactive Human Companions Who Walk and Talk with a User}},
booktitle = {IEEE Virtual Humans and Crowds for Immersive Environments (VHCIE)},
year = {2020},
month={March}
}
When Spatial Devices are not an Option : Object Manipulation in Virtual Reality using 2D Input Devices
With the advent of low-cost virtual reality hardware, new applications arise in professional contexts. These applications have requirements that can differ from the usual premise when developing immersive systems. In this work, we explore the idea that spatial controllers might not be usable for practical reasons, even though they are the best interaction device for the task. Such a reason might be fatigue, as applications might be used over a long period of time. Additionally, some people might have even more difficulty lifting their hands, due to a disability. Hence, we attempt to measure how much the performance in a spatial interaction task decreases when using classical 2D interaction devices instead of a spatial controller. For this, we developed an interaction technique that uses 2D inputs and borrows principles from desktop interaction. We show that our interaction technique is slower to use than the state-of-the-art spatial interaction but is not much worse regarding precision and user preference.
@inproceedings{Bellgardt2020,
author = {Bellgardt, Martin and Krause, Niklas and Kuhlen, Torsten W.},
booktitle = {Proc. of GI VR / AR Workshop},
title = {{When Spatial Devices are not an Option : Object Manipulation in Virtual Reality using 2D Input Devices}},
DOI = {10.18420/vrar2020_9}
year = {2020}
}
Towards a Graphical User Interface for Exploring and Fine-Tuning Crowd Simulations
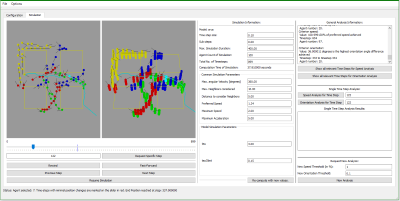
Simulating a realistic navigation of virtual pedestrians through virtual environments is a recurring subject of investigations. The various mathematical approaches used to compute the pedestrians’ paths result, i.a., in different computation-times and varying path characteristics. Customizable parameters, e.g., maximal walking speed or minimal interpersonal distance, add another level of complexity. Thus, choosing the best-fitting approach for a given environment and use-case is non-trivial, especially for novice users.
To facilitate the informed choice of a specific algorithm with a certain parameter set, crowd simulation frameworks such as Menge provide an extendable collection of approaches with a unified interface for usage. However, they often miss an elaborated visualization with high informative value accompanied by visual analysis methods to explore the complete simulation data in more detail – which is yet required for an informed choice. Benchmarking suites such as SteerBench are a helpful approach as they objectively analyze crowd simulations, however they are too tailored to specific behavior details. To this end, we propose a preliminary design of an advanced graphical user interface providing a 2D and 3D visualization of the crowd simulation data as well as features for time navigation and an overall data exploration.
@InProceedings{Boensch2020b,
author = {Andrea B\"{o}nsch and Marcel Jonda and Jonathan Ehret and Torsten W. Kuhlen},
title = {{Towards a Graphical User Interface for Exploring and Fine-Tuning Crowd Simulations}},
booktitle = {IEEE Virtual Humans and Crowds for Immersive Environments (VHCIE)},
year = {2020},
month={March}
}
Talk: Insite: A Generalized Pipeline for In-transit Visualization and Analysis
Neuronal network simulators are essential to computational neuroscience, enabling the study of the nervous system through in-silico experiments. Through utilization of high-performance computing resources, these simulators are able to simulate increasingly complex and large networks of neurons today. It also creates new challenges for the analysis and visualization of such simulations. In-situ and in-transport strategies are popular approaches in these scenarios. They enable live monitoring of running simulations and parameter adjustment in the case of erroneous configurations which can save valuable compute resources.
This talk will present the current status of our pipeline for in-transport analysis and visualization of neuronal network simulator data. The pipeline is able to couple with NEST along other simulators with data management (querying, filtering and merging) from multiple simulator instances. Finally, the data is passed to end-user applications for visualization and analysis. The goal is to be integrated into third party tools such as the multi-view visual analysis toolkit ViSimpl.
Talk: Proximity in Social VR - Interpersonal Distance between a User and Virtual Agents
Proxemic is a well known social behavioral measure, where the interpersonal distance between interactans is evaluated - either in real or in virtual social encounters. Given the prominent role of emotional expressions in our everyday social interactions, we investigated how emotions of a virtual agent affect proxemic adaptions while taking the aspects spatial constellation between user and agent as well as user’s level of dynamics into account.
SEG-MAT: 3D Shape Segmentation Using Medial Axis Transform

Segmenting arbitrary 3D objects into constituent parts that are structurally meaningful is a fundamental problem encountered in a wide range of computer graphics applications. Existing methods for 3D shape segmentation suffer from complex geometry processing and heavy computation caused by using low-level features and fragmented segmentation results due to the lack of global consideration. We present an efficient method, called SEG-MAT, based on the medial axis transform (MAT) of the input shape. Specifically, with the rich geometrical and structural information encoded in the MAT, we are able to develop a simple and principled approach to effectively identify the various types of junctions between different parts of a 3D shape. Extensive evaluations and comparisons show that our method outperforms the state-of-the-art methods in terms of segmentation quality and is also one order of magnitude faster.
@ARTICLE{9234096,
author={C. {Lin} and L. {Liu} and C. {Li} and L. {Kobbelt} and B. {Wang} and S. {Xin} and W. {Wang}},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={SEG-MAT: 3D Shape Segmentation Using Medial Axis Transform},
year={2020},
volume={},
number={},
pages={1-1},
doi={10.1109/TVCG.2020.3032566}}
DR-SPAAM: A Spatial-Attention and Auto-regressive Model for Person Detection in 2D Range Data

Detecting persons using a 2D LiDAR is a challenging task due to the low information content of 2D range data. To alleviate the problem caused by the sparsity of the LiDAR points, current state-of-the-art methods fuse multiple previous scans and perform detection using the combined scans. The downside of such a backward looking fusion is that all the scans need to be aligned explicitly, and the necessary alignment operation makes the whole pipeline more expensive -- often too expensive for real-world applications. In this paper, we propose a person detection network which uses an alternative strategy to combine scans obtained at different times. Our method, Distance Robust SPatial Attention and Auto-regressive Model (DR-SPAAM), follows a forward looking paradigm. It keeps the intermediate features from the backbone network as a template and recurrently updates the template when a new scan becomes available. The updated feature template is in turn used for detecting persons currently in the scene. On the DROW dataset, our method outperforms the existing state-of-the-art, while being approximately four times faster, running at 87.2 FPS on a laptop with a dedicated GPU and at 22.6 FPS on an NVIDIA Jetson AGX embedded GPU. We release our code in PyTorch and a ROS node including pre-trained models.
Jetson project of the month for September 2020
Previous Year (2019)
