
Publications
Mix3D: Out-of-Context Data Augmentation for 3D Scenes

Mix3D is a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well.
In the paper, we perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU.
@inproceedings{Nekrasov213DV,
title = {{Mix3D: Out-of-Context Data Augmentation for 3D Scenes}},
author = {Nekrasov, Alexey and Schult, Jonas and Or, Litany and Leibe, Bastian and Engelmann, Francis},
booktitle = {{International Conference on 3D Vision (3DV)}},
year = {2021}
}
From Points to Multi-Object 3D Reconstruction

We propose a method to detect and reconstruct multiple 3D objects from a single RGB image. The key idea is to optimize for detection, alignment and shape jointly over all objects in the RGB image, while focusing on realistic and physically plausible reconstructions. To this end, we propose a keypoint detector that localizes objects as center points and directly predicts all object properties, including 9-DoF bounding boxes and 3D shapes -- all in a single forward pass. The proposed method formulates 3D shape reconstruction as a shape selection problem, i.e. it selects among exemplar shapes from a given database. This makes it agnostic to shape representations, which enables a lightweight reconstruction of realistic and visually-pleasing shapes based on CAD-models, while the training objective is formulated around point clouds and voxel representations. A collision-loss promotes non-intersecting objects, further increasing the reconstruction realism. Given the RGB image, the presented approach performs lightweight reconstruction in a single-stage, it is real-time capable, fully differentiable and end-to-end trainable. Our experiments compare multiple approaches for 9-DoF bounding box estimation, evaluate the novel shape-selection mechanism and compare to recent methods in terms of 3D bounding box estimation and 3D shape reconstruction quality.
@inproceedings{Engelmann21CVPR,
title = {{From Points to Multi-Object 3D Reconstruction}},
author = {Engelmann, Francis and Rematas, Konstantinos and Leibe, Bastian and Ferrari, Vittorio},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2021}
}
3D Shape Generation with Grid-based Implicit Functions

Previous approaches to generate shapes in a 3D setting train a GAN on the latent space of an autoencoder (AE). Even though this produces convincing results, it has two major shortcomings. As the GAN is limited to reproduce the dataset the AE was trained on, we cannot reuse a trained AE for novel data. Furthermore, it is difficult to add spatial supervision into the generation process, as the AE only gives us a global representation. To remedy these issues, we propose to train the GAN on grids (i.e. each cell covers a part of a shape). In this representation each cell is equipped with a latent vector provided by an AE. This localized representation enables more expressiveness (since the cell-based latent vectors can be combined in novel ways) as well as spatial control of the generation process (e.g. via bounding boxes). Our method outperforms the current state of the art on all established evaluation measures, proposed for quantitatively evaluating the generative capabilities of GANs. We show limitations of these measures and propose the adaptation of a robust criterion from statistical analysis as an alternative.
@inproceedings {ibing20213Dshape,
title = {3D Shape Generation with Grid-based Implicit Functions},
author = {Ibing, Moritz and Lim, Isaak and Kobbelt, Leif},
booktitle = {IEEE Computer Vision and Pattern Recognition (CVPR)},
pages = {},
year = {2021}
}
Implicit Density Projection for Volume Conserving Liquids

We propose a novel implicit density projection approach for hybrid Eulerian/Lagrangian methods like FLIP and APIC to enforce volume conservation of incompressible liquids. Our approach is able to robustly recover from highly degenerate configurations and incorporates volume-conserving boundary handling. A problem of the standard divergence-free pressure solver is that it only has a differential view on density changes. Numerical volume errors, which occur due to large time steps and the limited accuracy of pressure projections, are invisible to the solver and cannot be corrected. Moreover, these errors accumulate over time and can lead to drastic volume changes, especially in long-running simulations or interactive scenarios. Therefore, we introduce a novel method that enforces constant density throughout the fluid. The density itself is tracked via the particles of the hybrid Eulerian/Lagrangian simulation algorithm. To achieve constant density, we use the continuous mass conservation law to derive a pressure Poisson equation which also takes density deviations into account. It can be discretized with standard approaches and easily implemented into existing code by extending the regular pressure solver. Our method enables us to relax the strict time step and solver accuracy requirements of a regular solver, leading to significantly higher performance. Moreover, our approach is able to push fluid particles out of solid obstacles without losing volume and generates more uniform particle distributions, which makes frequent particle resampling unnecessary. We compare the proposed method to standard FLIP and APIC and to previous volume correction approaches in several simulations and demonstrate significant improvements in terms of incompressibility, visual realism and computational performance.
@Article{BKKW21,
author = {Tassilo Kugelstadt and Andreas Longva and Nils Thuerey and Jan Bender},
title = {Implicit Density Projection for Volume Conserving Liquids},
journal = {IEEE Transactions on Visualization and Computer Graphics},
year = {2021},
publisher = {IEEE},
volume = {27},
number = {4},
doi={ 10.1109/TVCG.2019.2947437},
}
Do Prosody and Embodiment Influence the Perceived Naturalness of Conversational Agents' Speech?
presented at ACM Symposium on Applied Perception (SAP)

For conversational agents’ speech, all possible sentences have to be either prerecorded by voice actors or the required utterances can be synthesized. While synthesizing speech is more flexible and economic in production, it also potentially reduces the perceived naturalness of the agents amongst others due to mistakes at various linguistic levels. In our paper, we are interested in the impact of adequate and inadequate prosody, here particularly in terms of accent placement, on the perceived naturalness and aliveness of the agents. We compare (i) inadequate prosody, as generated by off-the-shelf text-to-speech (TTS) engines with synthetic output, (ii) the same inadequate prosody imitated by trained human speakers and (iii) adequate prosody produced by those speakers. The speech was presented either as audio-only or by embodied, anthropomorphic agents, to investigate the potential masking effect by a simultaneous visual representation of those virtual agents. To this end, we conducted an online study with 40 participants listening to four different dialogues each presented in the three Speech levels and the two Embodiment levels. Results confirmed that adequate prosody in human speech is perceived as more natural (and the agents are perceived as more alive) than inadequate prosody in both human (ii) and synthetic speech (i). Thus, it is not sufficient to just use a human voice for an agent’s speech to be perceived as natural - it is decisive whether the prosodic realisation is adequate or not. Furthermore, and surprisingly, we found no masking effect by speaker embodiment, since neither a human voice with inadequate prosody nor a synthetic voice was judged as more natural, when a virtual agent was visible compared to the audio-only condition. On the contrary, the human voice was even judged as less “alive” when accompanied by a virtual agent. In sum, our results emphasize on the one hand the importance of adequate prosody for perceived naturalness, especially in terms of accents being placed on important words in the phrase, while showing on the other hand that the embodiment of virtual agents plays a minor role in naturalness ratings of voices.
@article{Ehret2021a,
author = {Ehret, Jonathan and B\"{o}nsch, Andrea and Asp\"{o}ck, Lukas and R\"{o}hr, Christine T. and Baumann, Stefan and Grice, Martine and Fels, Janina and Kuhlen, Torsten W.},
title = {Do Prosody and Embodiment Influence the Perceived Naturalness of Conversational Agents’ Speech?},
journal = {ACM transactions on applied perception},
year = {2021},
issue_date = {October 2021},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {18},
number = {4},
articleno = {21},
issn = {1544-3558},
url = {https://doi.org/10.1145/3486580},
doi = {10.1145/3486580},
numpages = {15},
keywords = {speech, audio, accentuation, prosody, text-to-speech, Embodied conversational agents (ECAs), virtual acoustics, embodiment}
}
Being Guided or Having Exploratory Freedom: User Preferences of a Virtual Agent’s Behavior in a Museum

A virtual guide in an immersive virtual environment allows users a structured experience without missing critical information. However, although being in an interactive medium, the user is only a passive listener, while the embodied conversational agent (ECA) fulfills the active roles of wayfinding and conveying knowledge. Thus, we investigated for the use case of a virtual museum, whether users prefer a virtual guide or a free exploration accompanied by an ECA who imparts the same information compared to the guide. Results of a small within-subjects study with a head-mounted display are given and discussed, resulting in the idea of combining benefits of both conditions for a higher user acceptance. Furthermore, the study indicated the feasibility of the carefully designed scene and ECA’s appearance.
We also submitted a GALA video entitled "An Introduction to the World of Internet Memes by Curator Kate: Guiding or Accompanying Visitors?" by D. Hashem, A. Bönsch, J. Ehret, and T.W. Kuhlen, showcasing our application.
IVA 2021 GALA Audience Award!
@inproceedings{Boensch2021b,
author = {B\"{o}nsch, Andrea and Hashem, David and Ehret, Jonathan and Kuhlen, Torsten W.},
title = {{Being Guided or Having Exploratory Freedom: User Preferences of a Virtual Agent's Behavior in a Museum}},
year = {2021},
isbn = {9781450386197},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3472306.3478339},
doi = {10.1145/3472306.3478339},
booktitle = {{Proceedings of the 21th ACM International Conference on Intelligent Virtual Agents}},
pages = {33–40},
numpages = {8},
keywords = {virtual agents, enjoyment, guiding, virtual reality, free exploration, museum, embodied conversational agents},
location = {Virtual Event, Japan},
series = {IVA '21}
}
Learning Direction Fields for Quad Mesh Generation

State of the art quadrangulation methods are able to reliably and robustly convert triangle meshes into quad meshes. Most of these methods rely on a dense direction field that is used to align a parametrization from which a quad mesh can be extracted. In this context, the aforementioned direction field is of particular importance, as it plays a key role in determining the structure of the generated quad mesh. If there are no user-provided directions available, the direction field is usually interpolated from a subset of principal curvature directions. To this end, a number of heuristics that aim to identify significant surface regions have been proposed. Unfortunately, the resulting fields often fail to capture the structure found in meshes created by human experts. This is due to the fact that experienced designers can leverage their domain knowledge in order to optimize a mesh for a specific application. In the context of physics simulation, for example, a designer might prefer an alignment and local refinement that facilitates a more accurate numerical simulation. Similarly, a character artist may prefer an alignment that makes the resulting mesh easier to animate. Crucially, this higher level domain knowledge cannot be easily extracted from local curvature information alone. Motivated by this issue, we propose a data-driven approach to the computation of direction fields that allows us to mimic the structure found in existing meshes, which could originate from human experts or other sources. More specifically, we make use of a neural network that aggregates global and local shape information in order to compute a direction field that can be used to guide a parametrization-based quad meshing method. Our approach is a first step towards addressing this challenging problem with a fully automatic learning-based method. We show that compared to classical techniques our data-driven approach combined with a robust model-driven method, is able to produce results that more closely exhibit the ground truth structure of a synthetic dataset (i.e. a manually designed quad mesh template fitted to a variety of human body types in a set of different poses).
@article{dielen2021learning_direction_fields,
title={Learning Direction Fields for Quad Mesh Generation},
author={Dielen, Alexander and Lim, Isaak and Lyon, Max and Kobbelt, Leif},
year={2021},
journal={Computer Graphics Forum},
volume={40},
number={5},
}
Simpler Quad Layouts using Relaxed Singularities
A common approach to automatic quad layout generation on surfaces is to, in a first stage, decide on the positioning of irregular layout vertices, followed by finding sensible layout edges connecting these vertices and partitioning the surface into quadrilateral patches in a second stage. While this two-step approach reduces the problem's complexity, this separation also limits the result quality. In the worst case, the set of layout vertices fixed in the first stage without consideration of the second may not even permit a valid quad layout. We propose an algorithm for the creation of quad layouts in which the initial layout vertices can be adjusted in the second stage. Whenever beneficial for layout quality or even validity, these vertices may be moved within a prescribed radius or even be removed. Our algorithm is based on a robust quantization strategy, turning a continuous T-mesh structure into a discrete layout. We show the effectiveness of our algorithm on a variety of inputs.
@article{lyon2021simplerlayouts,
title={Simpler Quad Layouts using Relaxed Singularities},
author={Lyon, Max and Campen, Marcel and Kobbelt, Leif},
year={2021},
journal={Computer Graphics Forum},
volume={40},
number={5},
}
Surface Map Homology Inference

A homeomorphism between two surfaces not only defines a (continuous and bijective) geometric correspondence of points but also (by implication) an identification of topological features, i.e. handles and tunnels, and how the map twists around them. However, in practice, surface maps are often encoded via sparse correspondences or fuzzy representations that merely approximate a homeomorphism and are therefore inherently ambiguous about map topology. In this work, we show a way to infer topological information from an imperfect input map between two shapes. In particular, we compute a homology map, a linear map that transports homology classes of cycles from one surface to the other, subject to a global consistency constraint. Our inference robustly handles imperfect (e.g., partial, sparse, fuzzy, noisy, outlier-ridden, non-injective) input maps and is guaranteed to produce homology maps that are compatible with true homeomorphisms between the input shapes. Homology maps inferred by our method can be directly used to transfer homological information between shapes, or serve as foundation for the construction of a proper homeomorphism guided by the input map, e.g., via compatible surface decomposition.
- Best Paper Award at SGP 2021
- Graphics Replicability Stamp
@article{born2021surface,
title={Surface Map Homology Inference},
author={Born, Janis and Schmidt, Patrick and Campen, Marcel and Kobbelt, Leif},
year={2021},
journal={Computer Graphics Forum},
volume={40},
number={5},
}
Geodesic Distance Computation via Virtual Source Propagation

We present a highly practical, efficient, and versatile approach for computing approximate geodesic distances. The method is designed to operate on triangle meshes and a set of point sources on the surface. We also show extensions for all kinds of geometric input including inconsistent triangle soups and point clouds, as well as other source types, such as lines. The algorithm is based on the propagation of virtual sources and hence easy to implement. We extensively evaluate our method on about 10000 meshes taken from the Thingi10k and the Tet Meshing in the Wild data sets. Our approach clearly outperforms previous approximate methods in terms of runtime efficiency and accuracy. Through careful implementation and cache optimization, we achieve runtimes comparable to other elementary mesh operations (e.g. smoothing, curvature estimation) such that geodesic distances become a "first-class citizen" in the toolbox of geometric operations. Our method can be parallelized and we observe up to 6× speed-up on the CPU and 20× on the GPU. We present a number of mesh processing tasks easily implemented on the basis of fast geodesic distances. The source code of our method will be provided as a C++ library under the MIT license.
Note: we are currently in the process of cleaning up and documenting the source code. A basic implementation can already be found in the supplemental material.
Sampling from Quadric-Based CSG Surfaces

We present an efficient method to create samples directly on surfaces defined by constructive solid geometry (CSG) trees or graphs. The generated samples can be used for visualization or as an approximation to the actual surface with strong guarantees. We chose to use quadric surfaces as CSG primitives as they can model classical primitives such as planes, cubes, spheres, cylinders, and ellipsoids, but also certain saddle surfaces. More importantly, they are closed under affine transformations, a desirable property for a modeling system. We also propose a rendering method that performs local quadric ray-tracing and clipping to achieve pixel-perfect accuracy and hole-free rendering.
Layout Embedding via Combinatorial Optimization
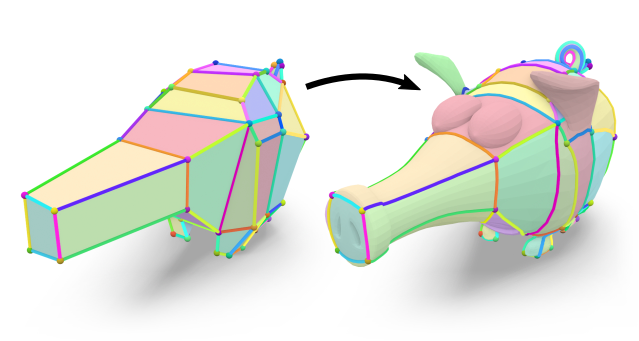
We consider the problem of injectively embedding a given graph connectivity (a layout) into a target surface. Starting from prescribed positions of layout vertices, the task is to embed all layout edges as intersection-free paths on the surface. Besides merely geometric choices (the shape of paths) this problem is especially challenging due to its topological degrees of freedom (how to route paths around layout vertices). The problem is typically addressed through a sequence of shortest path insertions, ordered by a greedy heuristic. Such insertion sequences are not guaranteed to be optimal: Early path insertions can potentially force later paths into unexpected homotopy classes. We show how common greedy methods can easily produce embeddings of dramatically bad quality, rendering such methods unsuitable for automatic processing pipelines. Instead, we strive to find the optimal order of insertions, i.e. the one that minimizes the total path length of the embedding. We demonstrate that, despite the vast combinatorial solution space, this problem can be effectively solved on simply-connected domains via a custom-tailored branch-and-bound strategy. This enables directly using the resulting embeddings in downstream applications which cannot recover from initializations in a wrong homotopy class. We demonstrate the robustness of our method on a shape dataset by embedding a common template layout per category, and show applications in quad meshing and inter-surface mapping.
@article{born2021layout,
title={Layout Embedding via Combinatorial Optimization},
author={Born, Janis and Schmidt, Patrick and Kobbelt, Leif},
year={2021},
journal={Computer Graphics Forum},
volume={40},
number={2},
}
MeTRAbs: Metric-Scale Truncation-Robust Heatmaps for Absolute 3D Human Pose Estimation

Heatmap representations have formed the basis of human pose estimation systems for many years, and their extension to 3D has been a fruitful line of recent research. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and Z to metric depth around the subject. To obtain metric-scale predictions, 2.5D methods need a separate post-processing step to resolve scale ambiguity. Further, they cannot localize body joints outside the image boundaries, leading to incomplete estimates for truncated images. To address these limitations, we propose metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are all defined in metric 3D space, instead of being aligned with image space. This reinterpretation of heatmap dimensions allows us to directly estimate complete, metric-scale poses without test-time knowledge of distance or relying on anthropometric heuristics, such as bone lengths. To further demonstrate the utility our representation, we present a differentiable combination of our 3D metric-scale heatmaps with 2D image-space ones to estimate absolute 3D pose (our MeTRAbs architecture). We find that supervision via absolute pose loss is crucial for accurate non-root-relative localization. Using a ResNet-50 backbone without further learned layers, we obtain state-of-the-art results on Human3.6M, MPI-INF-3DHP and MuPoTS-3D. Our code is publicly available to facilitate further research.
Winning submission at the ECCV 2020 3D Poses in the Wild Challenge
@article{Sarandi21metrabs,
title={{MeTRAbs:} Metric-Scale Truncation-Robust Heatmaps for Absolute {3D} Human Pose Estimation},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
journal={IEEE Transactions on Biometrics, Behavior, and Identity Science},
year={2021},
volume={3},
number={1},
pages={16--30}
}
Accurately Solving Rod Dynamics with Graph Learning

Iterative solvers are widely used to accurately simulate physical systems. These solvers require initial guesses to generate a sequence of improving approximate solutions. In this contribution, we introduce a novel method to accelerate iterative solvers for rod dynamics with graph networks (GNs) by predicting the initial guesses to reduce the number of iterations. Unlike existing methods that aim to learn physical systems in an end-to-end manner, our approach guarantees long-term stability and therefore leads to more accurate solutions. Furthermore, our method improves the run time performance of traditional iterative solvers for rod dynamics. To explore our method we make use of position-based dynamics (PBD) as a common solver for physical systems and evaluate it by simulating the dynamics of elastic rods. Our approach is able to generalize across different initial conditions, discretizations, and realistic material properties. We demonstrate that it also performs well when taking discontinuous effects into account such as collisions between individual rods. Finally, to illustrate the scalability of our approach, we simulate complex 3D tree models composed of over a thousand individual branch segments swaying in wind fields.
@inproceedings{Shao:2021:GraphLearning,
title={Accurately Solving Rod Dynamics with Graph Learning},
author={Han Shao and Tassilo Kugelstadt and Torsten H\"{a}drich and Wojciech Pa\l{}ubicki and Jan Bender and S\"{o}ren Pirk and Dominik L. Michels},
year={2021},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
URL={http://computationalsciences.org/publications/shao-2021-physical-systems-graph-learning.html}
}
Fast Corotated Elastic SPH Solids with Implicit Zero-Energy Mode Control

We develop a new operator splitting formulation for the simulation of corotated linearly elastic solids with Smoothed Particle Hydrodynamics (SPH). Based on the technique of Kugelstadt et al. [KKB2018] originally developed for the Finite Element Method (FEM), we split the elastic energy into two separate terms corresponding to stretching and volume conservation, and based on this principle, we design a splitting scheme compatible with SPH. The operator splitting scheme enables us to treat the two terms separately, and because the stretching forces lead to a stiffness matrix that is constant in time, we are able to prefactor the system matrix for the implicit integration step. Solid-solid contact and fluid-solid interaction is achieved through a unified pressure solve. We demonstrate more than an order of magnitude improvement in computation time compared to a state-of-the-art SPH simulator for elastic solids.
We further improve the stability and reliability of the simulation through several additional contributions. We introduce a new implicit penalty mechanism that suppresses zero-energy modes inherent in the SPH formulation for elastic solids, and present a new, physics-inspired sampling algorithm for generating high-quality particle distributions for the rest shape of an elastic solid. We finally also devise an efficient method for interpolating vertex positions of a high-resolution surface mesh based on the SPH particle positions for use in high-fidelity visualization.
@article{KBF+21,
author = {Kugelstadt, Tassilo and Bender, Jan and Fern{\'{a}}ndez-Fern{\'{a}}ndez, Jos{\'{e}} Antonio and Jeske, Stefan Rhys and L{\"{o}}schner, Fabian and Longva, Andreas},
title = {Fast Corotated Elastic SPH Solids with Implicit Zero-Energy Mode Control},
year = {2021},
issue_date = {September 2021},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {4},
number = {3},
url = {https://doi.org/10.1145/3480142},
doi = {10.1145/3480142},
journal = {Proc. ACM Comput. Graph. Interact. Tech.},
month = sep,
articleno = {33},
numpages = {21},
keywords = {Smoothed Particle Hydrodynamics, fluid simulation, deformable solids, solid-fluid coupling}
}
Compression and Rendering of Textured Point Clouds via Sparse Coding

Splat-based rendering techniques produce highly realistic renderings from 3D scan data without prior mesh generation. Mapping high-resolution photographs to the splat primitives enables detailed reproduction of surface appearance. However, in many cases these massive datasets do not fit into GPU memory. In this paper, we present a compression and rendering method that is designed for large textured point cloud datasets. Our goal is to achieve compression ratios that outperform generic texture compression algorithms, while still retaining the ability to efficiently render without prior decompression. To achieve this, we resample the input textures by projecting them onto the splats and create a fixed-size representation that can be approximated by a sparse dictionary coding scheme. Each splat has a variable number of codeword indices and associated weights, which define the final texture as a linear combination during rendering. For further reduction of the memory footprint, we compress geometric attributes by careful clustering and quantization of local neighborhoods. Our approach reduces the memory requirements of textured point clouds by one order of magnitude, while retaining the possibility to efficiently render the compressed data.
Design and Evaluation of a Free-Hand VR-based Authoring Environment for Automated Vehicle Testing

Virtual Reality is increasingly used for safe evaluation and validation of autonomous vehicles by automotive engineers. However, the design and creation of virtual testing environments is a cumbersome process. Engineers are bound to utilize desktop-based authoring tools, and a high level of expertise is necessary. By performing scene authoring entirely inside VR, faster design iterations become possible. To this end, we propose a VR authoring environment that enables engineers to design road networks and traffic scenarios for automated vehicle testing based on free-hand interaction. We present a 3D interaction technique for the efficient placement and selection of virtual objects that is employed on a 2D panel. We conducted a comparative user study in which our interaction technique outperformed existing approaches regarding precision and task completion time. Furthermore, we demonstrate the effectiveness of the system by a qualitative user study with domain experts.
Nominated for the Best Paper Award.
Quad Layouts via Constrained T-Mesh Quantization

We present a robust and fast method for the creation of conforming quad layouts on surfaces. Our algorithm is based on the quantization of a T-mesh, i.e. an assignment of integer lengths to the sides of a non-conforming rectangular partition of the surface. This representation has the benefit of being able to encode an infinite number of layout connectivity options in a finite manner, which guarantees that a valid layout can always be found. We carefully construct the T-mesh from a given seamless parametrization such that the algorithm can provide guarantees on the results' quality. In particular, the user can specify a bound on the angular deviation of layout edges from prescribed directions. We solve an integer linear program (ILP) to find a coarse quad layout adhering to that maximal deviation. Our algorithm is guaranteed to yield a conforming quad layout free of T-junctions together with bounded angle distortion. Our results show that the presented method is fast, reliable, and achieves high quality layouts.
@article{Lyon:2021:Quad,
title = {Quad Layouts via Constrained T-Mesh Quantization},
author = {Lyon, Max and Campen, Marcel and Kobbelt, Leif},
journal = {Computer Graphics Forum},
volume = {40},
number = {2},
year = {2021}
}
Reducing the Annotation Effort for Video Object Segmentation Datasets

For further progress in video object segmentation (VOS), larger, more diverse, and more challenging datasets will be necessary. However, densely labeling every frame with pixel masks does not scale to large datasets. We use a deep convolutional network to automatically create pseudo-labels on a pixel level from much cheaper bounding box annotations and investigate how far such pseudo-labels can carry us for training state-of-the-art VOS approaches. A very encouraging result of our study is that adding a manually annotated mask in only a single video frame for each object is sufficient to generate pseudo-labels which can be used to train a VOS method to reach almost the same performance level as when training with fully segmented videos. We use this workflow to create pixel pseudo-labels for the training set of the challenging tracking dataset TAO, and we manually annotate a subset of the validation set. Together, we obtain the new TAO-VOS benchmark, which we make publicly available at http://www.vision.rwth-aachen.de/page/taovos. While the performance of state-of-the-art methods on existing datasets starts to saturate, TAO-VOS remains very challenging for current algorithms and reveals their shortcomings.
@inproceedings{Voigtlaender21WACV,
title={Reducing the Annotation Effort for Video Object Segmentation Datasets},
author={Paul Voigtlaender and Lishu Luo and Chun Yuan and Yong Jiang and Bastian Leibe},
booktitle={WACV},
year={2021}
}
Poster: Indircet User Guidance by Pedestrians in Virtual Environments

Scene exploration allows users to acquire scene knowledge on entering an unknown virtual environment. To support users in this endeavor, aided wayfinding strategies intentionally influence the user’s wayfinding decisions through, e.g., signs or virtual guides.
Our focus, however, is an unaided wayfinding strategy, in which we use virtual pedestrians as social cues to indirectly and subtly guide users through virtual environments during scene exploration. We shortly outline the required pedestrians’ behavior and results of a first feasibility study indicating the potential of the general approach.
@inproceedings {Boensch2021a,
booktitle = {ICAT-EGVE 2021 - International Conference on Artificial Reality and Telexistence and Eurographics Symposium on Virtual Environments - Posters and Demos},
editor = {Maiero, Jens and Weier, Martin and Zielasko, Daniel},
title = {{Indirect User Guidance by Pedestrians in Virtual Environments}},
author = {Bönsch, Andrea and Güths, Katharina and Ehret, Jonathan and Kuhlen, Torsten W.},
year = {2021},
publisher = {The Eurographics Association},
ISSN = {1727-530X},
ISBN = {978-3-03868-159-5},
DOI = {10.2312/egve.20211336}
}
Poster: Virtual Optical Bench: A VR Learning Tool For Optical Design

The design of optical lens assemblies is a difficult process that requires lots of expertise. The teaching of this process today is done on physical optical benches, which are often too expensive for students to purchase. One way of circumventing these costs is to use software to simulate the optical bench. This work presents a virtual optical bench, which leverages real-time ray tracing in combination with VR rendering to create a teaching tool which creates a repeatable, non-hazardous, and feature-rich learning environment. The resulting application was evaluated in an expert review with 6 optical engineers.
@INPROCEEDINGS{Pape2021,
author = {Pape, Sebastian and Bellgardt, Martin and Gilbert, David and König, Georg and Kuhlen, Torsten W.},
booktitle = {2021 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW)},
title = {Virtual Optical Bench: A VR learning tool for optical design},
year = {2021},
volume ={},
number = {},
pages = {635-636},
doi = {10.1109/VRW52623.2021.00200}
}
Poster: Prosodic and Visual Naturalness of Dialogs Presented by Conversational Virtual Agents
Conversational virtual agents, with and without visual representation, are becoming more present in our daily life, e.g. as intelligent virtual assistants on smart devices. To investigate the naturalness of both the speech and the nonverbal behavior of embodied conversational agents (ECAs), an interdisciplinary research group was initiated, consisting of phoneticians, computer scientists, and acoustic engineers. For a web-based pilot experiment, simple dialogs between a male and a female speaker were created, with three prosodic conditions. For condition 1, the dialog was created synthetically using a text-to-speech engine. In the other two prosodic conditions (2,3) human speakers were recorded with 2) the erroneous accentuation of the text-to-speech synthesis of condition 1, and 3) with a natural accentuation. Face tracking data of the recorded speakers was additionally obtained and applied as input data for the facial animation of the ECAs. Based on the recorded data, auralizations in a virtual acoustic environment were generated and presented as binaural signals to the participants either in combination with the visual representation of the ECAs as short videos or without any visual feedback. A preliminary evaluation of the participants’ responses to questions related to naturalness, presence, and preference is presented in this work.
@inproceedings{Aspoeck2021,
author = {Asp\"{o}ck, Lukas and Ehret, Jonathan and Baumann, Stefan and B\"{o}nsch, Andrea and R\"{o}hr, Christine T. and Grice, Martine and Kuhlen, Torsten W. and Fels, Janina},
title = {Prosodic and Visual Naturalness of Dialogs Presented by Conversational Virtual Agents},
year = {2021},
note = {Hybride Konferenz},
month = {Aug},
date = {2021-08-15},
organization = {47. Jahrestagung für Akustik, Wien (Austria), 15 Aug 2021 - 18 Aug 2021},
url = {https://vr.rwth-aachen.de/publication/02207/}
}
Virtual Reality and Mixed Reality

We are pleased to present in this LNCS volume the scientific proceedings of EuroXR 2021, the 18th EuroXR International Conference, organized by CNR-STIIMA, Italy, which took place during November 24–26, 2021. Due to the COVID-19 pandemic, EuroXR 2021 was held as a virtual conference to guarantee the best audience while maintaining the safest conditions for the attendees. This conference follows a series of successful international conferences initiated in 2004 by the INTUITION Network of Excellence in Virtual and Augmented Reality, supported by the European Commission until 2008. Embedded within the Joint Virtual Reality Conference (JVRC) from 2009 to 2013, it was known as the EuroVR International Conference from 2014 and until last year. The focus of these conferences is to present, each year, novel Virtual Reality (VR) through to Mixed Reality (MR) technologies, also named eXtended Reality (XR), including software systems, immersive rendering technologies, 3D user interfaces, and applications. These conferences aim to foster European engagement between industry, academia, and the public sector, to promote the development and deployment of XR in new and emerging, but also existing, fields. Since 2017, EuroXR (https://www.euroxr-association.org/) has collaborated with Springer to publish the papers of the scientific track of our annual conference. To increase the excellence of this applied research conference, which is basically oriented toward new uses of XR technologies, we established a set of committees including Scientific Program chairs leading an International Program Committee (IPC) made up of international experts in the field. Eight scientific full papers have been selected to be published in the proceedings of EuroXR 2021, presenting original and unpublished papers documenting new XR research contributions, practice and experience, or novel applications. Five long papers and three medium papers were selected from 22 submissions, resulting in an acceptance rate of 36%. Within a double-blind peer reviewing process, three members of the IPC with the help of some external expert reviewers evaluated each submission. From the review reports of the IPC, the Scientific Program chairs took the final decisions. The selected scientific papers are organized in this LNCS volume according to four topical parts: Perception and Cognition, Interactive Techniques, Tracking and Rendering, and Use Case and User Study. Moreover, with the agreement of Springer and for the third year, the last part of this LNCS volume gathers scientific poster/short papers, presenting work in progress or other scientific contributions, such as ideas for unimplemented and/or unusual systems. Within another double-blind peer reviewing process based on two review reports from IPC members for each submission, the Scientific Program chairs selected four scientific poster/short papers from nine submissions (an acceptance rate of 44%). Along with the scientific track, presenting advanced research works (scientific full papers) or research works in progress (scientific poster/short papers) in this LNCS volume, several keynote speakers were invited to EuroXR 2021. Additionally, an application track, subdivided into talk, poster, and demo sessions, was organized for participants to report on the current use of XR technologies in multiple fields. We would like to thank the IPC members and external reviewers for their insightful reviews, which ensured the high quality of the papers selected for the scientific track of EuroXR 2021. Furthermore, we would like to thank the Application chairs, the Demo and Exhibition chairs, and the local organizers of EuroXR 2021. We are also especially grateful to Anna Kramer (Assistant Editor, Computer Science Editorial, Springer) and Volha Shaparava (Springer OCS Support) for their support and advice during the preparation of this LNCS volume.
September 2021
Patrick Bourdot Mariano Alcañiz Raya Pablo Figueroa Victoria Interrante Torsten W. Kuhlen Dirk Reiners
Talk: Numerical Analysis of Keratin Networks in Selected Cell Types

Keratin intermediate filaments make up the main intracellular cytoskeletal network of epithelia and provide, together with their associated desmosomal cell-cell adhesions, mechanical resilience. Remarkable differences in keratin network topology have been noted in different epithelial cell types ranging from a well-defined subapical network in enterocytes to pancytoplasmic networks in keratinocytes. In addition, functional states and biophysical, biochemical, and microbial stress have been shown to affect network organization. To gain insight into the importance of network topology for cellular function and resilience, quantification of 3D keratin network topology is needed.
We used Airyscan superresolution microscopy to record image stacks with an x/y resolution of 120 nm and axial resolution of 350 nm in canine kidney-derived MDCK cells, human epidermal keratinocytes, and murine retinal pigment epithelium (RPE) cells. Established segmentation algorithms (TSOAX) were implemented in combination with additional analysis tools to create a numerical representation of the keratin network topology in the different cell types. The resulting representation contains the XYZ position of all filament segment vertices together with data on filament thickness and information on the connecting nodes. This allows the statistical analysis of network parameters such as length, density, orientation, and mesh size. Furthermore, the network can be rendered in standard 3D software, which makes it accessible at hitherto unattained quality in 3D. Comparison of the three analyzed cell types reveals significant numerical differences in various parameters.
Listening to, and remembering conversations between two talkers: Cognitive research using embodied conversational agents in audiovisual virtual environments

In the AUDICTIVE project about listening to, and remembering the content of conversations between two talkers we aim to investigate the combined effects of potentially performance-relevant but scarcely addressed audiovisual cues on memory and comprehension for running speech. Our overarching methodological approach is to develop an audiovisual Virtual Reality testing environment that includes embodied Virtual Agents (VAs). This testing environment will be used in a series of experiments to research the basic aspects of audiovisual cognitive performance in a close(r)-to-real-life setting. We aim to provide insights into the contribution of acoustical and visual cues on the cognitive performance, user experience, and presence as well as quality and vibrancy of VR applications, especially those with a social interaction focus. We will study the effects of variations in the audiovisual ’realism’ of virtual environments on memory and comprehension of multi-talker conversations and investigate how fidelity characteristics in audiovisual virtual environments contribute to the realism and liveliness of social VR scenarios with embodied VAs. Additionally, we will study the suitability of text memory, comprehension measures, and subjective judgments to assess the quality of experience of a VR environment. First steps of the project with respect to the general idea of AUDICTIVE are presented.
@ inproceedings {Fels2021,
author = {Fels, Janina and Ermert, Cosima A. and Ehret, Jonathan and Mohanathasan, Chinthusa and B\"{o}nsch, Andrea and Kuhlen, Torsten W. and Schlittmeier, Sabine J.},
title = {Listening to, and Remembering Conversations between Two Talkers: Cognitive Research using Embodied Conversational Agents in Audiovisual Virtual Environments},
address = {Berlin},
publisher = {Deutsche Gesellschaft für Akustik e.V. (DEGA)},
pages = {1328-1331},
year = {2021},
booktitle = {[Fortschritte der Akustik - DAGA 2021, DAGA 2021, 2021-08-15 - 2021-08-18, Wien, Austria]},
month = {Aug},
date = {2021-08-15},
organization = {47. Jahrestagung für Akustik, Wien (Austria), 15 Aug 2021 - 18 Aug 2021},
url = {https://vr.rwth-aachen.de/publication/02206/}
}
Talk: Speech Source Directivity for Embodied Conversational Agents
Embodied conversational agents (ECAs) are computer-controlled characters who communicate with a human using natural language. Being represented as virtual humans, ECAs are often utilized in domains such as training, therapy, or guided tours while being embedded in an immersive virtual environment. Having plausible speech sound is thereby desirable to improve the overall plausibility of these virtual-reality-based simulations. In an audiovisual VR experiment, we investigated the impact of directional radiation for the produced speech on the perceived naturalism. Furthermore, we examined how directivity filters influence the perceived social presence of participants in interactions with an ECA. Therefor we varied the source directivity between 1) being omnidirectional, 2) featuring the average directionality of a human speaker, and 3) dynamically adapting to the currently produced phonemes. Our results indicate that directionality of speech is noticed and rated as more natural. However, no significant change of perceived naturalness could be found when adding dynamic, phoneme-dependent directivity. Furthermore, no significant differences on social presence were measurable between any of the three conditions.
Bibtex:
@misc{Ehret2021b,
author = {Ehret, Jonathan and Aspöck, Lukas and B\"{o}nsch, Andrea and Fels, Janina and Kuhlen, Torsten W.},
title = {Speech Source Directivity for Embodied Conversational Agents},
publisher = {IHTA, Institute for Hearing Technology and Acoustics},
year = {2021},
note = {Hybride Konferenz},
month = {Aug},
date = {2021-08-15},
organization = {47. Jahrestagung für Akustik, Wien (Austria), 15 Aug 2021 - 18 Aug 2021},
subtyp = {Video},
url = {https://vr.rwth-aachen.de/publication/02205/}
}
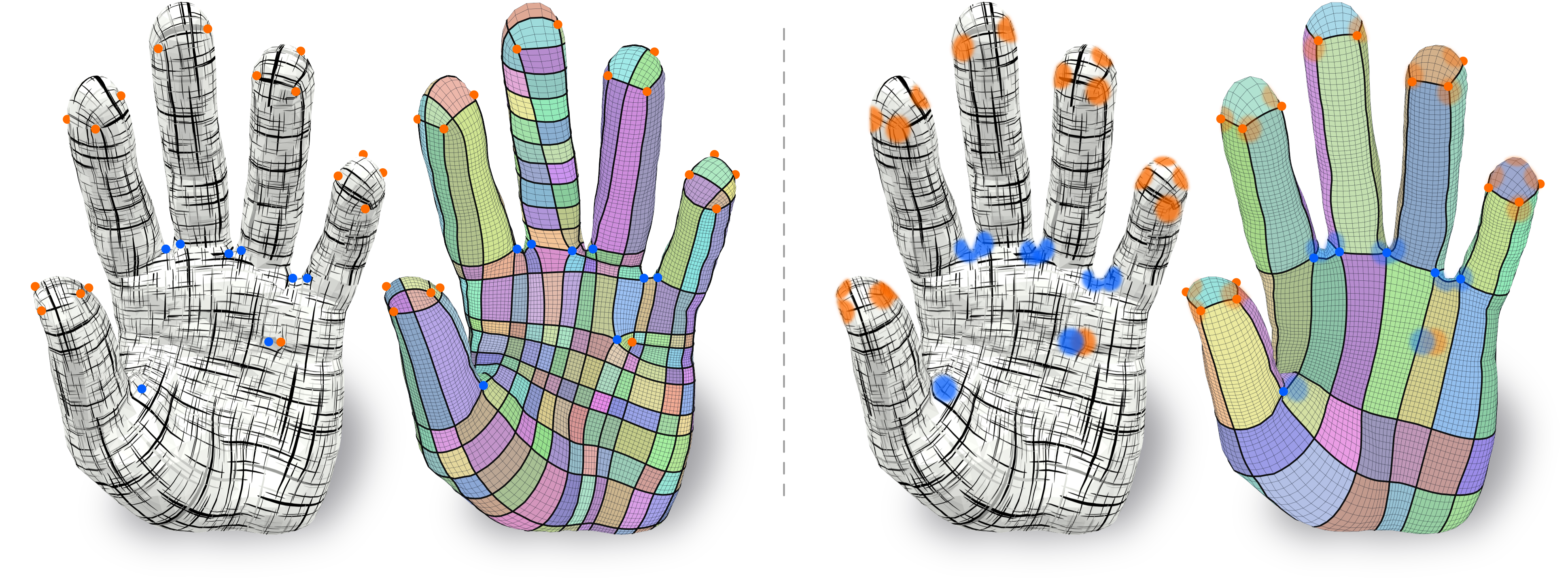
Intuitive Shape Editing in Latent Space
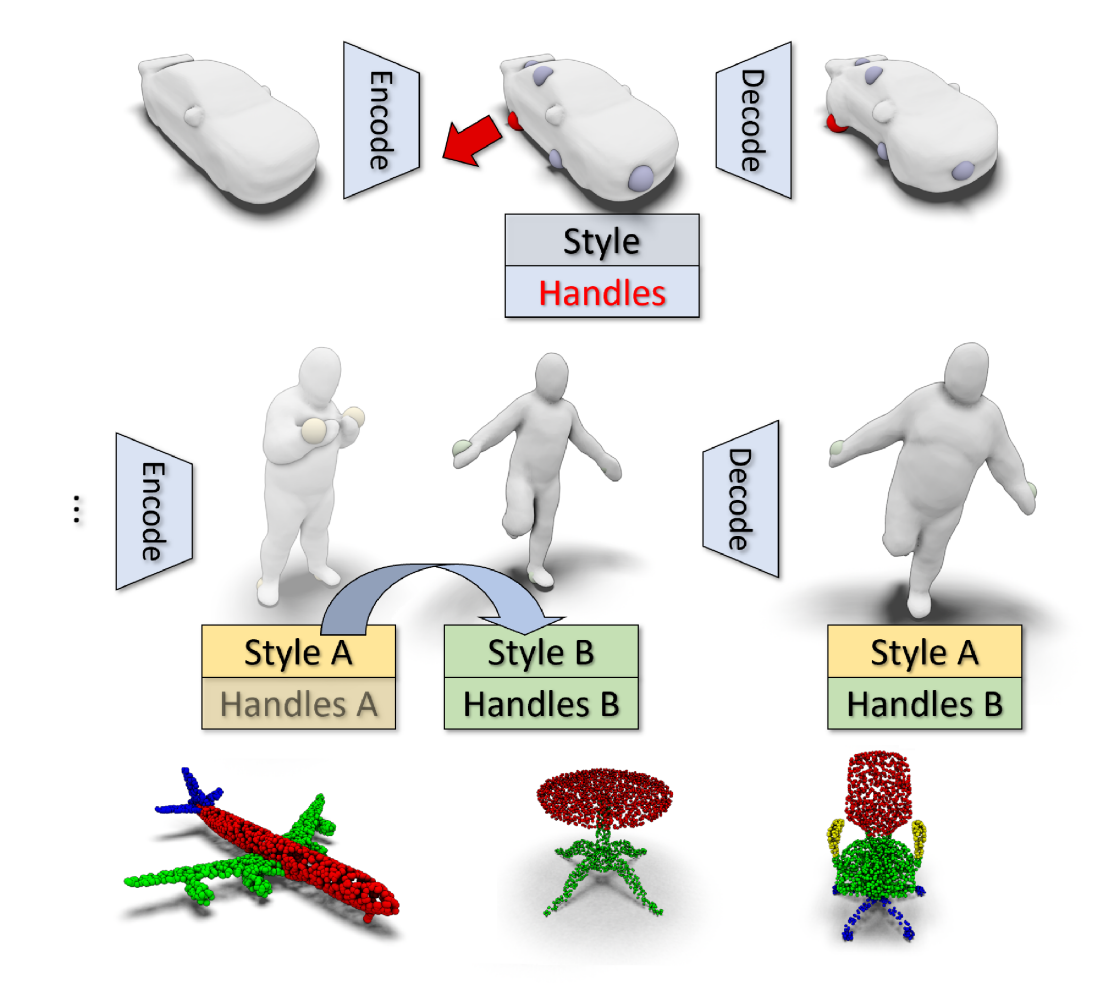
The use of autoencoders for shape editing or generation through latent space manipulation suffers from unpredictable changes in the output shape. Our autoencoder-based method enables intuitive shape editing in latent space by disentangling latent sub-spaces into style variables and control points on the surface that can be manipulated independently. The key idea is adding a Lipschitz-type constraint to the loss function, i.e. bounding the change of the output shape proportionally to the change in latent space, leading to interpretable latent space representations. The control points on the surface that are part of the latent code of an object can then be freely moved, allowing for intuitive shape editing directly in latent space. We evaluate our method by comparing to state-of-the-art data-driven shape editing methods. We further demonstrate the expressiveness of our learned latent space by leveraging it for unsupervised part segmentation.
Person-MinkUNet: 3D Person Detection with LiDAR Point Cloud
In this preliminary work we attempt to apply submanifold sparse convolution to the task of 3D person detection. In particular, we present Person-MinkUNet, a single-stage 3D person detection network based on Minkowski Engine with U-Net architecture. The network achieves a 76.4% average precision (AP) on the JRDB 3D detection benchmark.
Winner of JRDB 3D detection challenge in JRDB-ACT Workshop at CVPR 2021
Fast Exact Booleans for Iterated CSG using Octree-Embedded BSPs
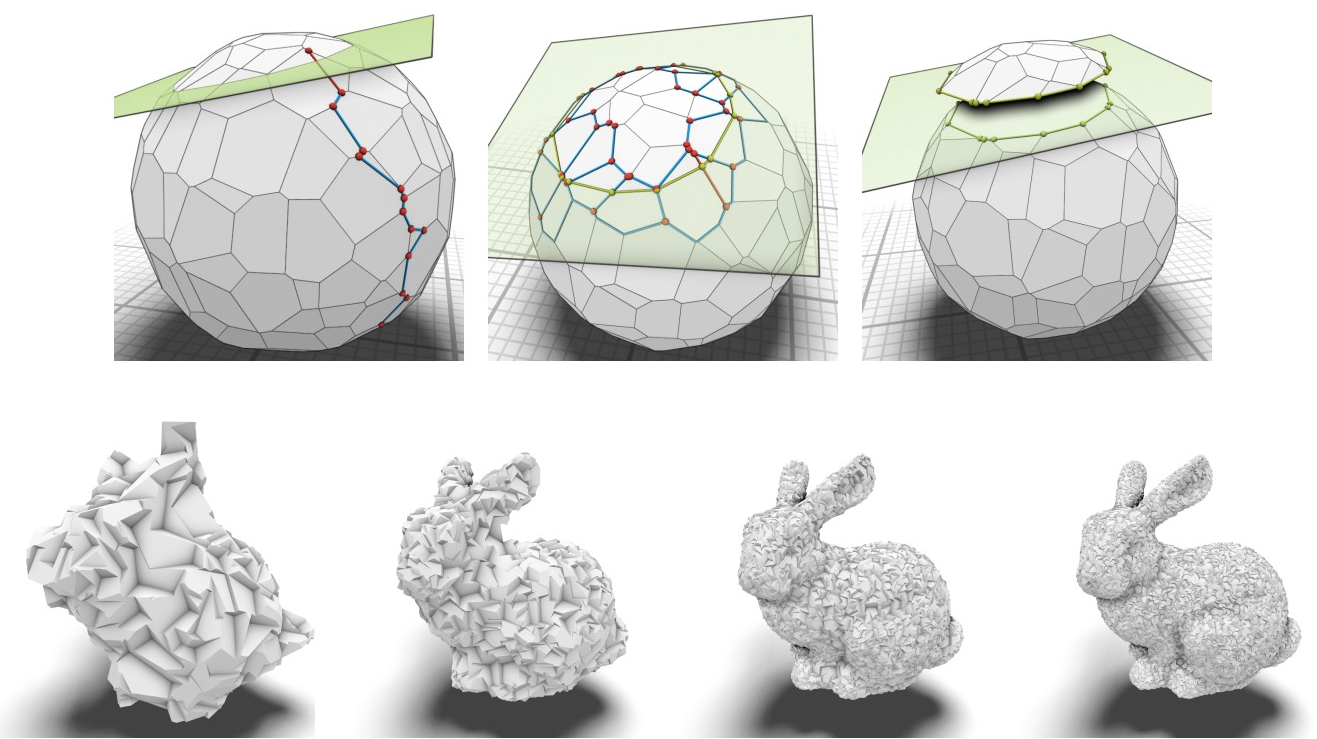
We present octree-embedded BSPs, a volumetric mesh data structure suited for performing a sequence of Boolean operations (iterated CSG) efficiently. At its core, our data structure leverages a plane-based geometry representation and integer arithmetics to guarantee unconditionally robust operations. These typically present considerable performance challenges which we overcome by using custom-tailored fixed-precision operations and an efficient algorithm for cutting a convex mesh against a plane. Consequently, BSP Booleans and mesh extraction are formulated in terms of mesh cutting. The octree is used as a global acceleration structure to keep modifications local and bound the BSP complexity. With our optimizations, we can perform up to 2.5 million mesh-plane cuts per second on a single core, which creates roughly 40-50 million output BSP nodes for CSG. We demonstrate our system in two iterated CSG settings: sweep volumes and a milling simulation.
@article{NEHRINGWIRXEL2021103015,
title = {Fast Exact Booleans for Iterated CSG using Octree-Embedded BSPs},
journal = {Computer-Aided Design},
volume = {135},
pages = {103015},
year = {2021},
issn = {0010-4485},
doi = {https://doi.org/10.1016/j.cad.2021.103015},
url = {https://www.sciencedirect.com/science/article/pii/S0010448521000269},
author = {Julius Nehring-Wirxel and Philip Trettner and Leif Kobbelt},
keywords = {Plane-based geometry, CSG, Mesh Booleans, BSP, Octree, Integer arithmetic},
abstract = {We present octree-embedded BSPs, a volumetric mesh data structure suited for performing a sequence of Boolean operations (iterated CSG) efficiently. At its core, our data structure leverages a plane-based geometry representation and integer arithmetics to guarantee unconditionally robust operations. These typically present considerable performance challenges which we overcome by using custom-tailored fixed-precision operations and an efficient algorithm for cutting a convex mesh against a plane. Consequently, BSP Booleans and mesh extraction are formulated in terms of mesh cutting. The octree is used as a global acceleration structure to keep modifications local and bound the BSP complexity. With our optimizations, we can perform up to 2.5 million mesh-plane cuts per second on a single core, which creates roughly 40-50 million output BSP nodes for CSG. We demonstrate our system in two iterated CSG settings: sweep volumes and a milling simulation.}
}
Self-Supervised Person Detection in 2D Range Data using a Calibrated Camera
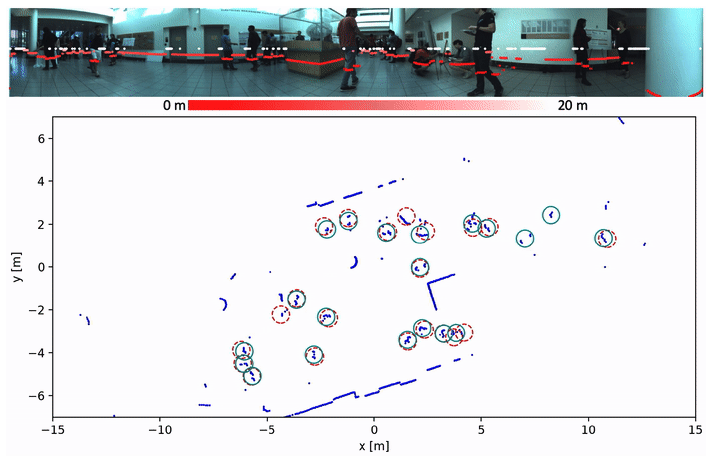
Deep learning is the essential building block of state-of-the-art person detectors in 2D range data. However, only a few annotated datasets are available for training and testing these deep networks, potentially limiting their performance when deployed in new environments or with different LiDAR models. We propose a method, which uses bounding boxes from an image-based detector (e.g. Faster R-CNN) on a calibrated camera to automatically generate training labels (called pseudo-labels) for 2D LiDAR-based person detectors. Through experiments on the JackRabbot dataset with two detector models, DROW3 and DR-SPAAM, we show that self- supervised detectors, trained or fine-tuned with pseudo-labels, outperform detectors trained using manual annotations from a different dataset. Combined with robust training techniques, the self-supervised detectors reach a performance close to the ones trained using manual annotations. Our method is an effective way to improve person detectors during deployment without any additional labeling effort, and we release our source code to support relevant robotic applications.
Previous Year (2020)
