
Publications
DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation

Vision foundation models (VFMs) trained on large-scale image datasets provide high-quality features that have significantly advanced 2D visual recognition. However, their potential in 3D scene segmentation remains largely untapped, despite the common availability of 2D images alongside 3D point cloud datasets. While significant research has been dedicated to 2D-3D fusion, recent state-of-the-art 3D methods predominantly focus on 3D data, leaving the integration of VFMs into 3D models underexplored. In this work, we challenge this trend by introducing DITR, a generally applicable approach that extracts 2D foundation model features, projects them to 3D, and finally injects them into a 3D point cloud segmentation model. DITR achieves state-of-the-art results on both indoor and outdoor 3D semantic segmentation benchmarks. To enable the use of VFMs even when images are unavailable during inference, we additionally propose to pretrain 3D models by distilling 2D foundation models. By initializing the 3D backbone with knowledge distilled from 2D VFMs, we create a strong basis for downstream 3D segmentation tasks, ultimately boosting performance across various datasets.
@InProceedings{knaebel2025ditr,
title = {{DINO} in the Room: Leveraging {2D} Foundation Models for {3D} Segmentation},
author = {Knaebel, Karim and Yilmaz, Kadir and de Geus, Daan and Hermans, Alexander and Adrian, David and Linder, Timm and Leibe, Bastian},
booktitle = {2026 International Conference on 3D Vision (3DV)},
year = {2026}
}
Self-supervised Learning of Fine-to-Coarse Cuboid Shape Abstraction
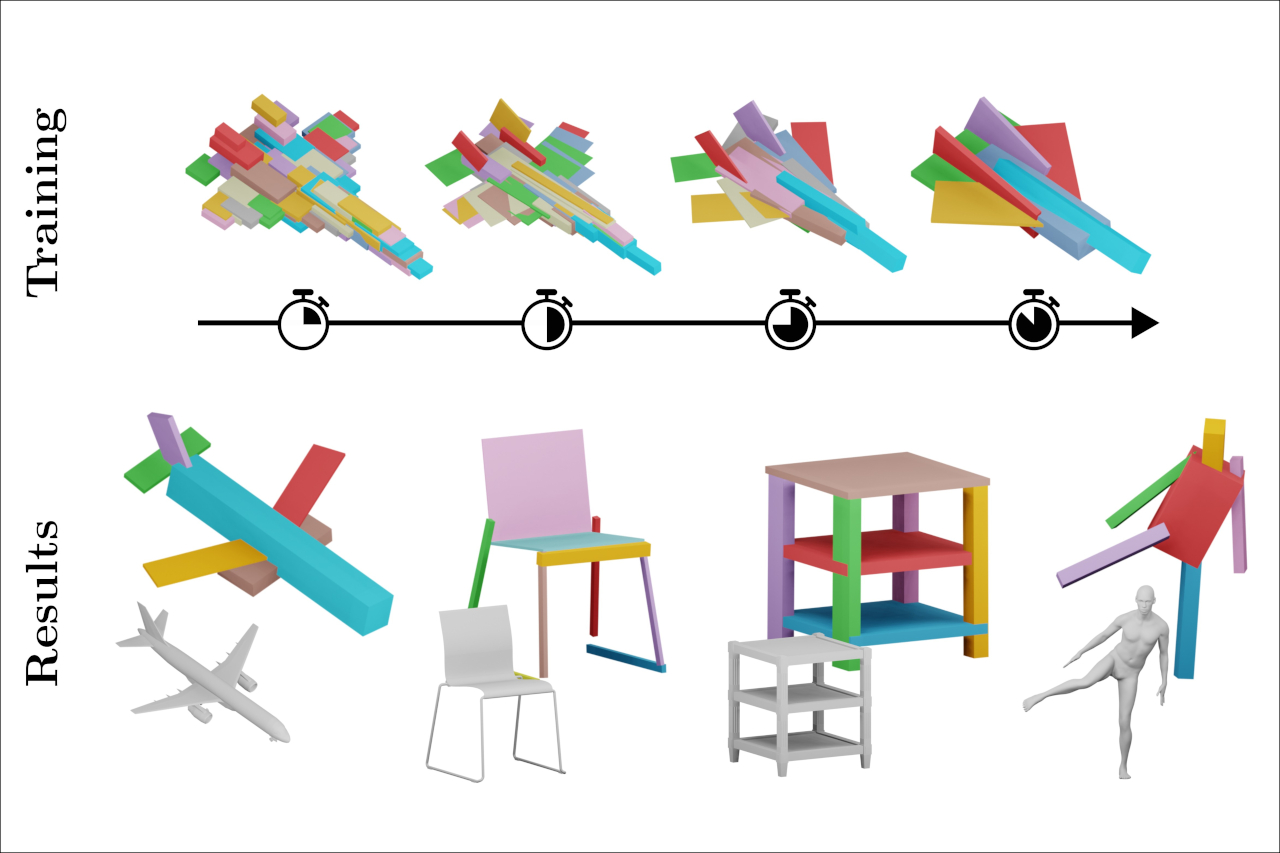
The abstraction of 3D objects with simple geometric primitives like cuboids allows us to infer structural information from complex geometry. It is important for 3D shape understanding, structural analysis and geometric modeling. We introduce a novel fine-to-coarse self-supervised learning approach to abstract collections of 3D shapes. Our architectural design allows us to reduce the number of primitives from hundreds (fine reconstruction) to only a few (coarse abstraction) during training. This allows our network to optimize the reconstruction error and adhere to a user-specified number of primitives per shape while simultaneously learning a consistent structure across the whole collection of data. We achieve this through our abstraction loss formulation which increasingly penalizes redundant primitives. Furthermore, we introduce a reconstruction loss formulation to account not only for surface approximation but also volume preservation. Combining both contributions allows us to represent 3D shapes more precisely with fewer cuboid primitives than previous work. We evaluate our method on collections of man-made and humanoid shapes comparing with previous state-of-the-art learning methods on commonly used benchmarks. Our results confirm an improvement over previous cuboid-based shape abstraction techniques. Furthermore, we demonstrate our cuboid abstraction in downstream tasks like clustering, retrieval, and partial symmetry detection
@article{kobsik2026cuboid,
title={Self-supervised Learning of Fine-to-Coarse Cuboid Shape Abstraction},
author={Kobsik, Gregor and Henkel, Morten and He, Yanjiang and Czech, Victor and Elsner, Tim and Lim, Isaak and Kobbelt, Leif},
year={2026},
journal={Computer Graphics Forum},
volume={45},
number={2},
}
Embedding Optimization of Layouts via Distortion Minimization

Given an embedding of a layout in the surface of a target mesh, we consider the problem of optimizing the embedding geometrically. Layout embeddings partition the surface into multiple disk-like patches, making them particularly useful for parametrization and remeshing tasks, such as quad-remeshing, since these problems can then be solved on simpler subdomains. Existing methods can either not guarantee to maintain patch connectivity, limiting downstream applications, or are specialized for quad layout optimization, relying on principal curvature information. We propose a framework that balances per-patch distortion minimization with strict connectivity control through an explicit representation. By inserting additional nodes along layout arcs, they can be embedded as piecewise geodesic curves on the surface. This sampling of arcs provides additional flexibility where required, enabling joint optimization of both node positions and arc embeddings. Our representation naturally supports a multi-resolution workflow: optimization on coarse meshes can be prolongated to high-resolution inputs. We demonstrate its effectiveness in applications requiring connectivity-preserving, low-distortion surface layouts.
@article{heuschling2026layoutOpt,
title={Embedding Optimization of Layouts via Distortion Minimization},
author={Heuschling, Alexandra and Lim, Isaak and Kobbelt, Leif},
year={2026},
journal={Computer Graphics Forum},
volume={45},
number={2},
}
Beyond Words: The Impact of Static and Animated Faces as Visual Cues on Memory Performance and Listening Effort during Two-Talker Conversations
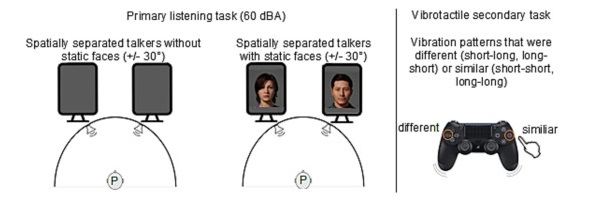
Listening to a conversation between two talkers and recalling the information is a common goal in verbal communication. However, cognitive-psychological experiments on short-term memory performance often rely on rather simple stimulus material, such as unrelated word lists or isolated sentences. The present study uniquely incorporated running speech, such as listening to a two-talker conversation, to investigate whether talker-related visual cues enhance short-term memory performance and reduce listening effort in non-noisy listening settings. In two equivalent dual-task experiments, participants listened to interrelated sentences spoken by two alternating talkers from two spatial positions, with talker-related visual cues presented as either static faces (Experiment 1, n = 30) or animated faces with lip sync (Experiment 2, n = 28). After each conversation, participants answered content-related questions as a measure of short-term memory (via the Heard Text Recall task). In parallel to listening, they performed a vibrotactile pattern recognition task to assess listening effort. Visual cue conditions (static or animated faces) were compared within-subject to a baseline condition without faces. To account for inter-individual variability, we measured and included individual working memory capacity, processing speed, and attentional functions as cognitive covariates. After controlling for these covariates, results indicated that neither static nor animated faces improved short-term memory performance for conversational content. However, static faces reduced listening effort, whereas animated faces increased it, as indicated by secondary task RTs. Participants' subjective ratings mirrored these behavioral results. Furthermore, working memory capacity was associated with short-term memory performance, and processing speed was associated with listening effort, the latter reflected in performance on the vibrotactile secondary task. In conclusion, this study demonstrates that visual cues influence listening effort and that individual differences in working memory and processing speed help explain variability in task performance, even in optimal listening conditions.
@article{MOHANATHASAN2026106295,
title = {Beyond words: The impact of static and animated faces as visual cues on memory performance and listening effort during two-talker conversations},
journal = {Acta Psychologica},
volume = {263},
pages = {106295},
year = {2026},
issn = {0001-6918},
doi = {https://doi.org/10.1016/j.actpsy.2026.106295},
url = {https://www.sciencedirect.com/science/article/pii/S0001691826000946},
author = {Chinthusa Mohanathasan and Plamenna B. Koleva and Jonathan Ehret and Andrea Bönsch and Janina Fels and Torsten W. Kuhlen and Sabine J. Schlittmeier}
}
HYVE: Hybrid Vertex Encoder for Neural Distance Fields

Neural shape representation generally refers to representing 3D geometry using neural networks, e.g., computing a signed distance or occupancy value at a specific spatial position. In this paper we present a neural-network architecture suitable for accurate encoding of 3D shapes in a single forward pass. Our architecture is based on a multi-scale hybrid system incorporating graph-based and voxel-based components, as well as a continuously differentiable decoder. The hybrid system includes a novel way of voxelizing point-based features in neural networks by projecting the point "feature-field" onto a grid. This projection is insensitive to local point density, and we show that it can be used to obtain smoother and more detailed reconstructions, in particular when combined with oriented point clouds as input. Our architecture also requires only a single forward pass, instead of the latent-code optimization used in auto-decoder methods. Furthermore, our network is trained to solve the well-established eikonal equation and only requires knowledge of the zero-level set for training and inference. We additionally propose a modification to the aforementioned loss function for the case that surface normals are not well defined, e.g., in the context of non-watertight surfaces and non-manifold geometry. Overall, our method consistently outperforms other baselines on the surface reconstruction task across a wide variety of datasets, while being more computationally efficient and requiring fewer parameters.
@article{jeskeHYVEHybridVertex2026,
title = {{{HYVE}}: {{Hybrid Vertex Encoder}} for {{Neural Distance Fields}}},
shorttitle = {{{HYVE}}},
author = {Jeske, Stefan R. and Klein, Jonathan and Michels, Dominik and Bender, Jan},
year = 2026,
journal = {IEEE Transactions on Visualization and Computer Graphics},
doi = {10.1109/TVCG.2026.3658870},
copyright = {https://ieeexplore.ieee.org/Xplorehelp/downloads/license-information/IEEE.html}
}
Previous Year (2025)
